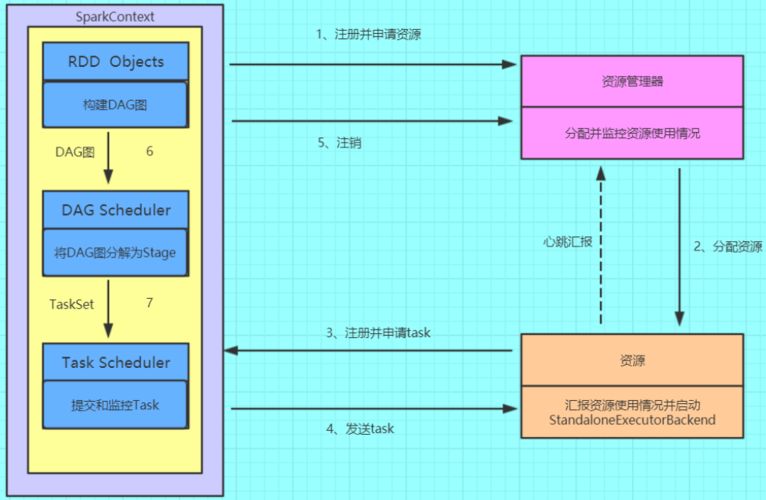
前言:由于最近对spark的运行流程非常感兴趣,所以阅读了《Spark大数据处理:技术、应用与性能优化》一书。通过这本书的学习,了解了spark的核心技术、实际应用场景以及性能优化的方法。本文旨在记录和分享下spark运行的基本流程。一、spark的基础组件及其概念1. ClusterManager在Standalone模式中即为Master,控制整个集群,监控Worker。在YARN模式中为资源管理器。2. Application用户自定义的spark程序, 用户提交后, Spark为App分配资源, 将程序转换并执行。3. Driver在Spark中,driver是一个核心概念,指的是Spark应用程序的主进程,也称为主节点。负责运行Application的main( ) 函数并创建SparkContext。4. Worker从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。5. Executor执行器,在Worker节点上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。6. RDD GraphRDD是spark的核心结构, 可以通过一系列算子进行操作( 主要有Transformation和Action操作) 。 当RDD遇到Action算子时, 将之前的所有算子形成一个有向无环图( DAG) , 也就是RDD Graph。 再在Spark中转化为Job, 提交到集群执行。一个App中可以包含多个Job。7. Job一个RDD Graph触发的作业, 往往由Spark Action算子触发, 在SparkContext中通过runJob方法向Spark提交Job。8. Stage每个Job会根据RDD的宽依赖关系被切分很多Stage, 每个Stage中包含一组相同的Task, 这一组Task也叫TaskSet。9. Task一个分区对应一个Task, Task执行RDD中对应Stage中包含的算子。 Task被封装好后放入Executor的线程池中执行。二、spark架构spark架构采用了分布式计算中的Master-Slave模型。Master作为整个集群的控制器,负责整个集群的正常运行;Worker相当于是计算节点,接收主节点命令与进行状态汇报;Executor负责任务的执行;Client作为用户的客户端负责提交应用,Driver负责控制一个应用的执行。如图所示,spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个spark应用的执行过程中,Driver和Worker是两个重要角色。Driver程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。三、Spark的工作机制1. Spark的整体流程Client提交应用,Master找到一个Worker启动Driver,Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph,再由DAG Scheduler将RDD Graph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。如图所示,在spark应用中,整个执行流程在逻辑上会形成有向无环图。Action算子触发之后,将所有累计的算子形成一个有向无环图,然后由调度器调度该图上的任务进行运算。spark根据RDD之间不同的依赖关系切分形成不同的阶段(stage),一个阶段包含一系列函数执行流水线。途中A、B、C、D、E、F、分别代表不同的RDD,RDD内的方框代表分区。数据从HDFS输入spark,形成RDD A和RDD C,RDD C上执行map操作,转换为RDD D,RDD B和RDD E执行Join操作,转换为F。而在B和E连接转化为F的过程中又会执行Shuffle,最后RDD F通过函数saveAsSequenceFile输出并保存到HDFS中。2. Stage的划分如上面这个运行流程所示,在 Apache Spark 中,一个作业(Job)通常会被划分为多个阶段(Stage),每个阶段包含一组并行的任务(Task)。这种划分主要是基于数据宽窄依赖进行的,以便更有效地进行任务调度和执行。以下是关于 Spark 中 Stage 划分的一些关键点:•宽窄依赖窄依赖(Narrow Dependency):父 RDD 的每个分区只会被一个子 RDD 的分区使用,或者多个子 RDD 分区计算时都使用同一个父 RDD 分区。窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区,不会造成网络之间的数据混洗。宽依赖(Wide Dependency):父 RDD 的每个分区都可能被多个子 RDD 分区所使用,会引起 shuffle。•Stage的划分Spark 根据 RDD 之间的宽窄依赖关系来划分 Stage。遇到宽依赖就划分一个 Stage,每个 Stage 里面包含多个 Task,Task 的数量由该 Stage 最后一个 RDD 的分区数决定。一个 Stage 内部的多个 Task 可以并行执行,而 Stage 之间是串行执行的。只有当一个 Stage 中的所有 Task 都计算完成后,才会开始下一个 Stage 的计算。•Shuffle 与 Stage 边界当 Spark 遇到一个宽依赖(如 `reduceByKey`、`groupBy` 等操作)时,它需要在该操作之前和之后分别创建一个新的 Stage。这是因为宽依赖需要 shuffle 数据,而 shuffle 通常涉及磁盘 I/O,因此将宽依赖作为 Stage 之间的边界可以提高效率。3. Stage和Task调度方式Stage的调度是由DAGScheduler完成的。 由RDD的有向无环图DAG切分出了Stage的有向无环图DAG。 Stage的DAG通过最后执行Stage为根进行广度优先遍历, 遍历到最开始执行的Stage执行, 如果提交的Stage仍有未完成的父母Stage, 则Stage需要等待其父Stage执行完才能执行。 同时DAGScheduler中还维持了几个重要的Key-Value集合构, 用来记录Stage的状态, 这样能够避免过早执行和重复提交Stage。waitingStages中记录仍有未执行的父母Stage, 防止过早执行。 runningStages中保存正在执行的Stage, 防止重复执行。failedStages中保存执行失败的Stage, 需要重新执行。每个Stage包含一组并行的Task,这些Task被组织成TaskSet(任务集合)。DAGScheduler将划分好的TaskSet提交给TaskScheduler。TaskScheduler是负责Task调度和集群资源管理的组件。TaskScheduler通过TaskSetManager来管理每个TaskSet。TaskSetManager会跟踪和控制其管辖的Task的执行,包括任务的启动、状态监控和失败重试等。当TaskSet被提交到TaskScheduler时,TaskScheduler会决定在哪些Executor上运行Task,并通过集群管理器(如YARN、Mesos或Spark Standalone)将Task分发到相应的节点上执行。Executor接收到Task后,会在其管理的线程池中执行任务。执行过程中,Task的状态会不断更新,并通过状态更新机制通知TaskSetManager。TaskSetManager根据接收到的状态更新来跟踪Task的执行情况,如遇到任务失败,会触发重试机制直至达到设定的重试次数。当所有Task都执行完成后,TaskScheduler会通知DAGScheduler,并由DAGScheduler负责触发后续Stage的执行(如果存在)。4. Shuffle机制为什么spark计算模型需要Shuffle过程? 我们都知道, spark计算模型是在分布式的环境下计算的, 这就不可能在单进程空间中容纳所有的计算数据来进行计算, 这样数据就按照Key进行分区, 分配成一块一块的小分区, 打散分布在集群的各个进程的内存空间中, 并不是所有计算算子都满足于按照一种方式分区进行计算。 例如, 当需要对数据进行排序存储时, 就有了重新按照一定的规则对数据重新分区的必要, Shuffle就是包裹在各种需要重分区的算子之下的一个对数据进行重新组合的过程。 如图, 整个Job分为Stage1~Stage3, 3个Stage。首先从最上端的Stage2、 Stage3执行, 每个Stage对每个分区执行变换( transformation) 的流水线式的函数操作, 执行到每个Stage最后阶段进行Shuffle Write,将数据重新根据下一个Stage分区数分成相应的Bucket, 并将Bucket最后写入磁盘。 这个过程就是Shuffle Write阶段。执行完Stage2、 Stage3之后, Stage1去存储有Shuffle数据节点的磁盘Fetch需要的数据, 将数据Fetch到本地后进行用户定义的聚集函数操作。 这个阶段叫Shuffle Fetch, Shuffle Fetch包含聚集阶段。 这样一轮一轮的Stage之间就完成了Shuffle操作。四、结语在阅读《Spark大数据处理:技术、应用与性能优化》一书后,我大概了解了spark的运行机制及原理。上文仅是做了一个简单的总结,而且并没有对一些细节进行深入解读。在原书中有着十分详细的介绍,包含其容错、IO、网络等机制以及从源码解析spark的运行流程,而且书中通过大量实际案例,展示了如何在具体应用中使用Spark进行数据处理、分析和挖掘,使理论与实践相结合,大家如有兴趣可自行阅读。







0 评论