
{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_36338224/article/details/111936614"],"selectors":[{"clickElementSelector":"li.js-page-next","clickElementUniquenessType":"uniqueText","clickType":"clickMore","delay":2000,"discardInitialElements":"do-not-discard","id":"next_page","multiple":true,"parentSelectors":["_root","next_page"],"selector":"div.comment-list-container","type":"SelectorElementClick"},{"delay":0,"id":"comment","multiple":true,"parentSelectors":["_root","next_page"],"selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","type":"SelectorElement"},{"delay":0,"id":"content","multiple":false,"parentSelectors":["comment"],"regex":"","selector":"_parent_","type":"SelectorText"}]}JSONCopy当然啦,对于分页这种事情,web scraper 提供了更专业的 Pagination 选择器,它的配置更为精简,效果也最好对应的 sitemap 的配置如下,你可以直接导入使用{"_id":"blog_comment","startUrl":["https://blog.csdn.net/weixin_36338224/article/details/111936614"],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"comment","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"ul:nth-of-type(n+2) > li.comment-line-box span.new-comment","multiple":true,"delay":0},{"id":"content","parentSelectors":["comment"],"type":"SelectorText","selector":"_parent_","multiple":false,"delay":0,"regex":""}]}JSONCopy要重载页面的分页器爬取CSDN 的博客文章列表,拉到底部,点击具体的页面按钮,或者最右边的下一页就会重载当前的页面而对于这种分页器,Element Click 就无能为力了,读者可自行验证一下,最多只能爬取一页就会关闭了而作为为分页而生的 Pagination 选择器自然是适用的爬取的拓扑与上面都是一样的,这里不再赘述对应的 sitemap 的配置如下,你可以直接导入去学习{"_id":"mycsdn","startUrl":["https://blog.csdn.net/weixin_36338224/article/list/1"],"selectors":[{"id":"next_page","parentSelectors":["_root","next_page"],"paginationType":"auto","selector":"li.js-page-next","type":"SelectorPagination"},{"id":"article","parentSelectors":["_root","next_page"],"type":"SelectorElement","selector":"div.article-item-box","multiple":true,"delay":0},{"id":"title","parentSelectors":["article"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":"[0-9]+"},{"id":"comments","parentSelectors":["article"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""},{"id":"publish_time","parentSelectors":["article"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""}]}JSONCopy4. 二级页面的爬取CSDN 的博客列表列表页,展示的信息比较粗糙,只有标题、发表时间、阅读量、评论数,是否原创想要获取更多的信息,诸如博文的正文、点赞数、收藏数、评论区内容,就得点进去具体的博文链接进行查看web scraper 的操作逻辑与人是相通的,想要抓取更多博文的详细信息,就得打开一个新的页面去获取,而 web scraper 的 Link 选择器恰好就是做这个事情的爬取路径拓扑如下爬取的效果如下sitemap 的配置如下,你可以直接导入使用{"_id":"csdn_detail","startUrl":["https://blog.csdn.net/weixin_36338224/article/list/1"],"selectors":[{"id":"container","parentSelectors":["_root"],"type":"SelectorElement","selector":"[data-articleid='111936614']","multiple":false,"delay":0},{"id":"article_detail_link","parentSelectors":["container"],"type":"SelectorLink","selector":"h4 a","multiple":false,"delay":0},{"id":"detail","parentSelectors":["article_detail_link"],"type":"SelectorText","selector":"article","multiple":false,"delay":0,"regex":""},{"id":"title","parentSelectors":["container"],"type":"SelectorText","selector":"h4 a","multiple":false,"delay":0,"regex":""},{"id":"time","parentSelectors":["container"],"type":"SelectorText","selector":"span.date","multiple":false,"delay":0,"regex":""},{"id":"views","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(2)","multiple":false,"delay":0,"regex":""},{"id":"comments","parentSelectors":["container"],"type":"SelectorText","selector":"span:nth-of-type(3)","multiple":false,"delay":0,"regex":""}]}JSONCopy5. 写在最后上面梳理了分页与二级页面的爬取方案,主要是:分页器抓取和二级页面抓取只要学会了这两个,你就已经可以应对绝大多数的结构性网页数据了例如你可以爬取自己发表在 CSDN 上的所有博文信息,包括:标题、链接、文章内容、阅读数,评论数、点赞数,收藏数当然想要用好 web scraper 这个零代码爬取工具,你可能需要有一些基础,比如:CSS 选择器的知识:如何抓取元素的属性,如何抓取第 n 个元素,如何抓取指定数量的元素?正则表达式的知识:如何对抓取的内容进行初步加工?受限于篇幅,我尽量讲 web scraper 最核心的操作,其他的基础内容只能由大家自行充电学习了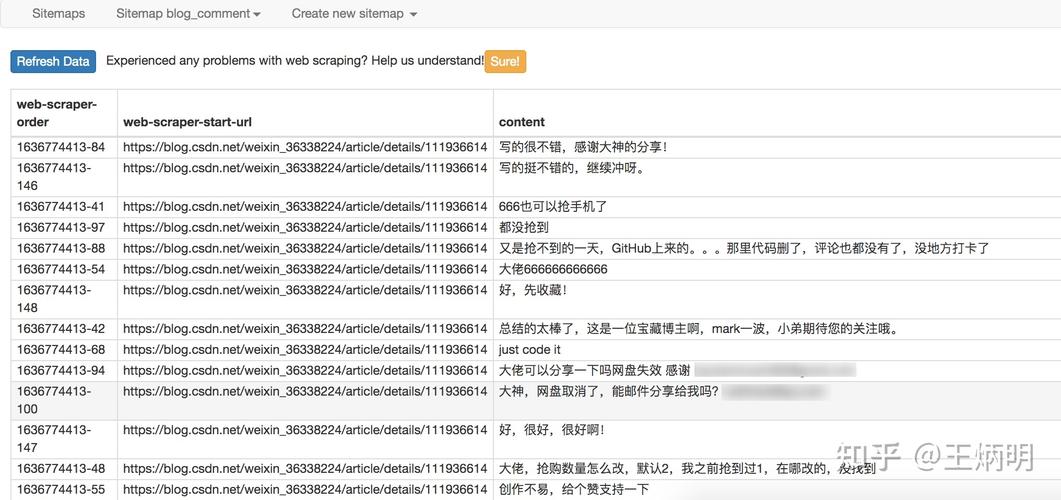
(图片来源网络,侵删)







0 评论