
{ "name" : "hello world", "sex" : 0, "email": "10086@qq.com" "age" : 20}关系数据库 ⇒ 数据库(database) ⇒ 表(table) ⇒ 行 (row) ⇒ 列(Columns)Elasticsearch ⇒索引(index) ⇒类型(type) ⇒文档(docments) ⇒字段(fields)4.优势Elasticsearch可以存放大量数据,Elasticsearch集群非常容易横向扩展,而且检索性能非常好,在大数据量的情况下相比于mysql等性能上有很大的优势,下面的几个优势:横向可扩展性:只需要增加台服务器或者添加节点,在分布式配置中心更新配置,启动Elasticsearch的服务器就可以并入集群。分片机制提供更好的分布性:同一个索引分成多个分片(sharding), 这点类似于分布式文件系统的块机制;分而治之的方式可提升处理效率。高可用:提供复制( replica) 机制,一个分片可以设置多个复制,使得某台服务器在宕机的情况下,集群仍旧可以照常运行,并会把服务器宕机丢失的数据信息复制恢复到其他可用节点上。 使用简单:只需一条命令就可以下载文件,然后很快就能搭建一一个站内搜索引擎。5.与solr对比 docker pull elasticsearch:6.4.3 docker pull mobz/elasticsearch-head:5 docker pull kibana:6.4.31.2 运行容器 run: docker run -it --name elasticsearch -d -p 9200:9200 -p 9300:9300 -p 5601:5601 -e ES_JAVA_OPTS="-Xms256m -Xmx256m" elasticsearch:6.4.3注意事项kibana的container共用elasticsearch的网络elasticsearch服务有跨域问题,导致elasticsearch-head无法连接到ES,因此需要进入ES容器修改配置1.3 运行的容器中执行命令:docker exec -it elasticsearch /bin/bashvi config/elasticsearch.yml加入跨域配置http.cors.enabled: truehttp.cors.allow-origin: ""退出容器:exitdocker restart elasticsearchdocker run -it -d -e ELASTICSEARCH_URL=http://ip:9200 --name kibana --network=container:elasticsearch kibana:6.4.3docker run -it --name elasticsearch-head -d -p 9100:9100 docker.io/mobz/elasticsearch-head:5 2.Linux搭建1、安装Elasticsearch1、 安装JDK环境变量export JAVA_HOME=/usr/local/jdk1.8.0_181export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarsource /etc/profile2、 下载elasticsearch安装包下载elasticsearch安装包官方文档注意:linux安装内存建议1g内存以上3、 上传elasticsearch安装包(这里使用xshell 与 xshell ftp)4、 解压elasticsearchtar -zxvf elasticsearch-6.4.3.tar.gz5、 修改elasticsearch.ymlnetwork.host: 对应本地iphttp.port: 92006、启动elasticsearch报错cd /usr/local/elasticsearch-6.4.3/bin./elasticsearch可能出现的错误:这里出现的错误借鉴网络报错1:can not run elasticsearch as root解决方案:因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户第1:liunx创建新用户,然后给创建的用户加密码,输入两次密码。第2:切换刚才创建的用户,然后执行elasticsearch,会显示Permission denied 权限不足。第3:给新建的用户赋权限,chmod 777 这个不行,因为这个用户本身就没有权限,肯定自己不能给自己付权限。所以要用root用户登录付权限。第4:root给用户赋权限,chown -R XXX /你的elasticsearch安装目录。然后执行成功。 下面一些操作:groupadd user_groupuseradd username-g user_group -p 123456chown -R username:user_group elasticsearch-6.4.3 chown -R username:user_group 切换用户:su username ./elasticsearch报错2:bootstrap checks failed max virtual memory areas vm.max_map_count [65530] is vi /etc/sysctl.confvm.max_map_count=655360sysctl -p ./elasticsearch报错3:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]vi /etc/security/limits.conf soft nofile 65536 hard nofile 131072 soft nproc 2048 hard nproc 4096重启服务器即可 记得,这个很重要。./elasticsearch7、访问elasticsearch关闭防火墙,可以的话设置永久关闭防火墙,自行百度systemctl stop firewalld.service中途可能会出现很多坑,记得小心,我搭建倒是没有这么多问题,我朋友的就出现了挺多的http://ip:92002、安装Kibana1、下载2、上传,解压tar -zxvf kibana-6.4.3-linux-x86_64.tar.gz3、配置vim config/kibana.yml# 将默认配置改成如下:server.port: 5601server.host: "你的ip" #elasticsearch的服务elasticsearch.url: "http:// 你的ip:9200"4、启动Kibana./bin/kibana5、运行http://ip:5601三、整合使用1、Kibana基本使用GET _search{ "query": { "match_all": {} }}# 索引index 类型type 文档document 属性fieldPUT /gitboy/user/1{ "name":"hello", "sex":1, "age":22}PUT /gitboy/user/2{ "name":"hello2", "sex":1, "age":22}GET /gitboy/user/1基本索引的命令以及操作可以借鉴我上一篇文章2、Springboot整合搭建新建工程什么的就不说了,直接来吧。2.1引入pom文件的依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.0.RELEASE</version><relativePath /> <!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>2.2 application.ymlspring: data: elasticsearch: ####集群名称 cluster-name: elasticsearch ####地址 cluster-nodes: 139.196.81.0:93002.3 pojo@Document(indexName = "cluster_name索引", type = "user")//注意cluster_name索引@Datapublic class UserEntity {@Idprivate String id;private String name;private int sex;private int age;}2.4 daopublic interface UserReposiory extends CrudRepository<UserEntity, String> {}2.5 servicepublic interface UserService { public UserEntity addUser( UserEntity user); public Optional<UserEntity> findUser(String id);}@Servicepublic class UserServiceImpl implements UserService { @Autowiredprivate UserReposiory userReposiory; @Override public UserEntity addUser(UserEntity user) {return userReposiory.save(user);}@Overridepublic Optional<UserEntity> findUser(String id) {return userReposiory.findById(id);}}2.6 controller@RestControllerpublic class UserController {@Autowiredprivate UserService userService;@RequestMapping("/addUser")public UserEntity addUser(@RequestBody UserEntity user) {return userService.save(user);}@RequestMapping("/findUser")public Optional<UserEntity> findUser(String id) {return userService.findById(id);}}2.7启动@SpringBootApplication@EnableElasticsearchRepositories(basePackages = "com.example.repository")public class AppEs {public static void main(String[] args) {SpringApplication.run(AppEs.class, args);}}四、分词1、什么是分词器因为Elasticsearch中默认的标准分词器分词器对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉子。因此引入中文分词器-es-ik插件2、下载与配置下载地址: github.com/medcl/elast…注意: es-ik分词插件版本一定要和es安装的版本对应第一步:下载es的IK插件(资料中有)命名改为ik插件第二步: 上传到/usr/local/elasticsearch-6.4.3/plugins第三步: 重启elasticsearch即可3、自定义扩展字典在/usr/local/elasticsearch-6.4.3/plugins/ik/config目录下3.1 新建文件vi custom/new_word.dic吃鸡王者荣耀码云马云3.2 配置vi IKAnalyzer.cfg.xml<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">custom/new_word.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>五、文档映射已经把ElasticSearch的核心概念和关系数据库做了一个对比,索引(index)相当于数据库,类型(type)相当于数据表,映射(Mapping)相当于数据表的表结构。ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。文档映射就是给文档中的字段指定字段类型、分词器。使用GET /gitboy/user/_mapping1、映射的分类1.1 动态映射我们知道,在关系数据库中,需要事先创建数据库,然后在该数据库实例下创建数据表,然后才能在该数据表中插入数据。而ElasticSearch中不需要事先定义映射(Mapping),文档写入ElasticSearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。1.2 静态映射在ElasticSearch中也可以事先定义好映射,包含文档的各个字段及其类型等,这种方式称之为静态映射。2、ES类型支持2.1 基本类型符串:string,string类型包含 text 和 keyword。text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索)。注意: keyword类型不能分词,Text类型可以分词查询数指型:long、integer、short、byte、double、float日期型:date布尔型:boolean二进制型:binary数组类型(Array datatype)2.2 复杂类型地理位置类型(Geo datatypes)地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状2.3 特定类型(Specialised datatypes)Pv4 类型(IPv4 datatype):ip 用于IPv4 地址Completion 类型(Completion datatype):completion 提供自动补全建议Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等Analyzer 索引分词器,索引创建的时候使用的分词器 比如ik_smartSearch_analyzer 搜索字段的值时,指定的分词器六 、倒排索引1、正向索引正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。2、倒排索引倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。作者:xuchang_2020链接:https://juejin.cn/post/6844903874487123976来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。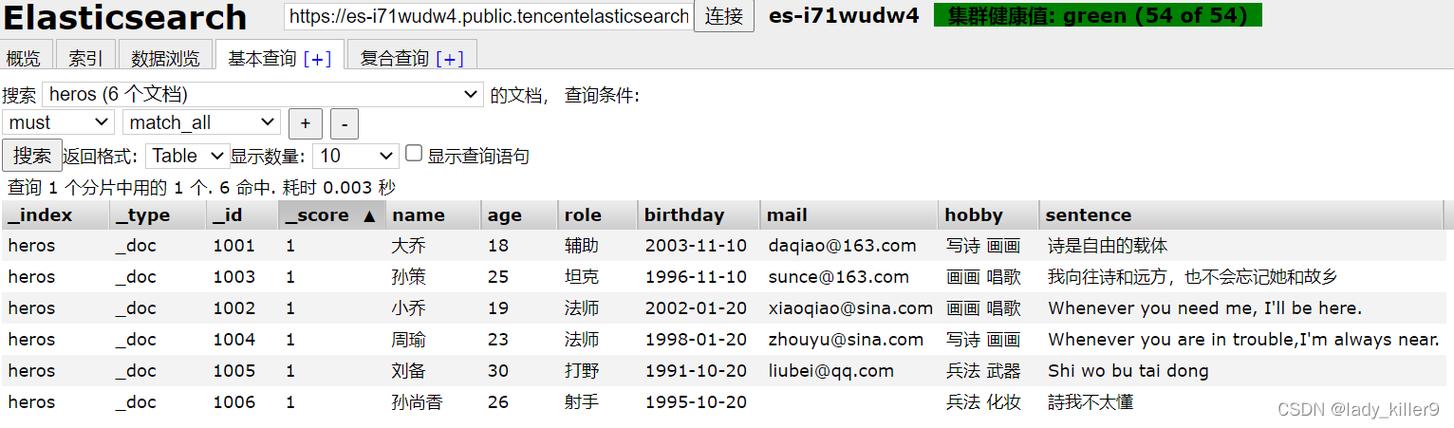
(图片来源网络,侵删)




0 评论