- APP神圣官网 > 软件快讯 > 正文
分词手把手中文教你用Jieba(分词模式中文文本精确)「jieba分词工具三种分词模式」
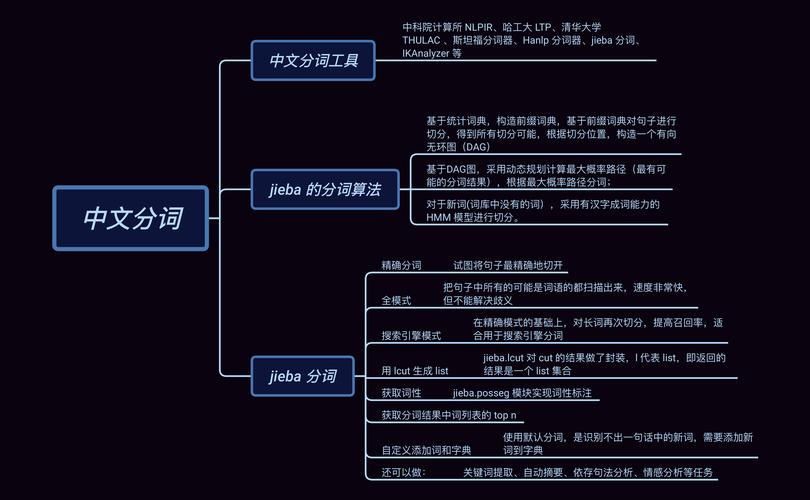
导读:近年来,随着NLP技术日益成熟,开源实现的分词工具越来越多,如Ansj、HanLP、盘古分词等本文我们选取了Jieba进行介绍作者:杜振东 涂铭来源:华章科技01 Jieba的特点1. 社区活跃Jieba在GitHub上已经有25.3k的star数目社区活跃度高,代表着该项目会持续更新,能够长期使用,用户在实际生产实践中遇到的问题也能够在社区进行反馈并得到解决2. 功能丰富Jieba并不是只有分词这一个功能,它是一个开源框架,提供了很多在分词之上的算法,如关键词提取、词性标注等3. 提供多种编程语言实现Jieba官方提供了Python、C++、Go、R、iOS等多平台多语言支持,不仅如此,还提供了很多热门社区项目的扩展插件,如ElasticSearch、solr、lucene等在实际项目中,使用Jieba进行扩展十分容易4. 使用简单Jieba的API总体来说并不多,且需要进行的配置并不复杂,适合新手上手下载完成后,可以使用如下命令进行安装pipinstalljiebaJieba分词结合了基于规则和基于统计两类方法首先基于前缀词典进行词图扫描,前缀词典是指词典中的词按照前缀包含的顺序排列,如词典中出现了“上”,之后以“上”开头的词都会出现在一起,如词典中出现“上海”一词,进而会出现“上海市”等词,从而形成一种层级包含结构如果将词看作节点,词和词之间的分词符看作边,那么一种分词方案则对应着从第一个字到最后一个字的一条分词路径因此,基于前缀词典可以快速构建包含全部可能分词结果的有向无环图,这个图包含多条分词路径,有向是指全部的路径都始于第一个字、止于最后一个字,无环是指节点之间不构成闭环其次,基于标注语料、使用动态规划的方法可以找出最大概率路径,并将其作为最终的分词结果对于未登录词,Jieba使用了基于汉字成词的HMM模型,采用了Viterbi算法进行推导02 Jieba的3种分词模式Jieba提供了以下3种分词模式精确模式:试图将句子精确地切开,适合文本分析全模式:把句子中所有可以成词的词语都扫描出来全模式处理速度非常快,但是不能解决歧义搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词下面是使用这3种模式的对比importjiebasent='中文分词是文本处理不可或缺的一步
'seg_list=jieba.cut(sent,cut_all=True)print('全模式:','/'.join(seg_list))seg_list=jieba.cut(sent,cut_all=False)print('精确模式:','/'.join(seg_list))seg_list=jieba.cut(sent)print('默认精确模式:','/'.join(seg_list))seg_list=jieba.cut_for_search(sent)print('搜索引擎模式','/'.join(seg_list))运行结果如下所示全模式:中文/分词/是/文本/文本处理/本处/处理/不可/不可或缺/或缺/的/一步//精确模式:中文/分词/是/文本处理/不可或缺/的/一步/
默认精确模式:中文/分词/是/文本处理/不可或缺/的/一步/
搜索引擎模式中文/分词/是/文本/本处/处理/文本处理/不可/或缺/不可或缺/的/一步/!可以看到,在全模式和搜索引擎模式下,Jieba会把分词的所有可能都打印出来一般直接使用精确模式即可,但是在某些模糊匹配场景下,使用全模式或搜索引擎模式更适合关于作者:杜振东,国家标准委人工智能技术专家和AIIA(中国人工智能产业发展联盟)技术专家拥有8年机器学习与文本挖掘相关技术经验,6年中文自然语言处理相关项目实战经验,擅长PyTorch、TensorFlow等主流深度学习框架,擅长运用NLP前沿技术解决真实项目的难题涂铭,数据架构师和人工智能技术专家,曾就职于阿里,现就职于腾讯对大数据、自然语言处理、图像识别、Python、Java等相关技术有深入的研究,积累了丰富的实践经验本文摘编自《会话式AI:自然语言处理与人机交互》,经出版方授权发布延伸阅读《会话式AI:自然语言处理与人机交互》推荐语:腾讯、国家标准委AI专家撰写,详解NLP和人机交互,从算法、实战3维度讲解聊天机器人原理、实现与工程实践
联系我们
在线咨询:







0 评论