什么是软件系统的稳定性软件系统的稳定性指的是软件系统在各种压力条件下,能够保持其正常运行的能力具体来说,软件系统的稳定性包括以下几个方面:容错性:处理各种异常情况的能力,例如输入不规范、数据错误等负载能力:在不同的负载条件下,保持其正常运行的能力稳定性:性能不会因为用户数量的增加而下降,即具有可扩展性可靠性:能够在不同的环境下,长时间稳定运行的能力安全性:能够抵御各种攻击的能力软件系统的稳定性是衡量一个软件质量的重要指标之一,它直接影响到用户的使用体验和企业运营的可靠性软件系统不稳定可能带来的后果数据丢失:如果软件系统崩溃或出现故障,企业的数据可能会丢失,这可能会对企业的运作和管理产生灾难性的影响例如,如果ERP软件不稳定,可能会影响企业数据的安全性和可靠性生产线停滞:如果企业的ERP系统不稳定,可能会导致生产线的停滞,从而使企业无法生产和出货,进而影响企业利润和声誉客户服务不及时:如果企业的ERP系统不够稳定,很多时候企业可能无法及时响应客户的请求,这可能会破坏企业客户忠诚度和推广效果例如,如果电商网站宕机,可能会影响用户体验和销售业绩信誉受损:如果软件系统经常出现故障或崩溃,可能会让用户对软件开发商或软件本身产生不信任感,从而影响其市场声誉和竞争力法律纠纷:如果因为软件系统的不稳定导致了用户数据的泄露或损失,软件开发商可能要承担相应的法律责任,面临法律纠纷经济损失:如果软件系统不稳定导致企业无法正常运营或开展业务,将会给企业带来直接和间接的经济损失例如,系统故障可能会导致企业无法按时交付订单或提供服务,从而给企业带来经济损失因此,软件系统的稳定性对于企业的运营和业务发展至关重要在选择软件开发商或开发团队时,企业应该注重其技术实力和经验,以确保所开发的软件系统能够稳定运行并为企业带来长期效益软件开发过程中的重要环节系统稳定性建设是软件开发过程中的重要环节,它涉及到多个方面,包括需求分析、设计、编码、测试、部署等以下是一些关于系统稳定性建设的建议:在需求分析阶段,需要明确系统的功能需求和非功能需求,包括系统的稳定性、可靠性、可扩展性等同时,需要对系统的用户需求进行分析和评估,以确保系统能够满足用户的需求在系统设计阶段,需要根据需求分析的结果,采用合适的设计方法和架构,设计出稳定、可靠的软件系统例如,可以采用分层架构、微服务架构等,以实现系统的可扩展性和稳定性在编码阶段,需要采用良好的编程习惯和代码规范,编写出高质量的代码同时,需要采用单元测试和集成测试等测试方法,以确保代码的质量和系统的稳定性在测试阶段,需要采用多种测试方法,包括功能测试、性能测试、压力测试等,以确保系统的稳定性和可靠性同时,需要对测试结果进行分析和评估,以发现和修复系统中的潜在问题在部署阶段,需要对系统进行部署和配置,以确保系统能够正常运行同时,需要对系统的运行情况进行监控和维护,及时发现和解决系统的问题和故障维护和优化:在系统上线后,需要对系统进行维护和优化工作,以确保系统的稳定性和可靠性同时,需要对用户的反馈和评价进行分析和评估,以发现和改进系统中的不足之处2. 故障源的分类系统的故障源一般可以分为两大类,一类是人为因素,另一类是自然因素常见人为因素导致的故障如下:人为因素我们要尽可能的 事前(故障发生前)避免,因为这些原因引发的事故很可能会导致数据丢失或错乱、资金受损等较严重后果,而且除了重启或修复后重新上线外没有过多有效的止损手段常见的自然因素导致的故障如下:自然因素受很多客观因素的影响,往往不受控制,无法避免3. 稳定性建设四要素“如果事情有变坏的可能,不管这种可能性有多小,它总会发生”,残酷的墨菲定律预示着我们对自己系统提供的服务不要太乐观,接下来,我们说说如何建设系统稳定性,人为因素的根源一方面是专业能力不足,经验不足,另一方面很多都是无心之失,所以需要通过流程、规范来保住“底线”,减少人为因素导致的故障,而自然因素导致的故障往往具有突发性,需要联合多个团队协作来解决故障稳定性建设四要素:人、工具、预案和目标第一要素:人稳定性建设工作实施一般需要 开发、测试、运维、安全 还有 产品 等同学参与,而且主导方应该是开发、测试和运维规范先行根据公司的当前技术体系去建设 开发规范、提测规范、测试规范、上线规范、复盘规范 等我们拿和软件开发最相关的开发规范来说,开发规范是对开发人员的要求,让开发人员知道什么是必须要做的、什么是推荐的、什么是应该避免的通常开发规范至少应该包括如下几个部分:编码规范:对外接口命名方式、统一异常父类、业务异常码规范、对外提供服务不可用是抛异常还是返回错误码、统一第三方库的版本、哪些场景必须使用内部公共库、埋点日志怎么打、提供统一的日志、监控切面实现等,编码规范除了能规范开发的编码行为、避免犯一些低级错误和踩一些重复的坑外,另一个好处是让新入职的同学能快速了解公司的编码原则,这点对编码快速上手很重要公共库使用规范:为了能对通用功能进行定制化改造和封装,公司内部肯定会有一些公共库,例如日志库、HTTP 库、线程池库、监控埋点库等,这些库都“久经考验”,已经被证实是有效且可靠的,这些就应该强制使用,当然为了适应业务的发展,这些公共库也应该进行迭代和升级项目结构规范:为了贯彻标准的项目结构,一方面我们需要为各种类型项目通过“项目脚手架”来创建标准的项目结构原型,然后基于这个项目原型来进行开发,统一的项目结构一个最显著的好处是让开发能快速接手和了解项目,这种对于团队内维护多个项目很重要,人员能进行快速补位数据库规范:数据库连接资源堪比 CPU 资源,现在的应用都离不开数据库,而且通常数据库都属于核心资源,一旦数据库不可用,应用都没有太有效的止损手段,所以在数据库规范里,库名、表名、索引、字段、分库分表的一些规范都必须明确第二要素:工具强大的支持工具和平台是不可缺少的,常见的工具和平台包括:日志采集分析检索平台、监控告警平台、分布式追踪系统、自动化打包部署平台、服务降级系统、预案平台、根因定位平台、放火平台等第三要素:预案紧急预案是我们在故障发生时的行动指南,这在故障可能涉及到多个团队、故障进展需要周知到多个团队时特别有用紧急预案一般要包含如下内容:故障发生时应该通知哪些人或团队如何选出协调者,什么情况下该选出协调者协调者的职责有哪些需要操作开关时,谁有权利决策常见故障以及对应的止损方式止损的原则是什么,什么是最重要的善后方案谁来拍板预案很重要,完备的预案能降低故障定位和止损的时间,提升协作效率第四要素:目标如何衡量稳定性建设工作是有价值的?如何考核稳定性建设工作达没达标、做的好不好?这些都能在稳定性建设的目标中找到答案稳定性建设工作的价值不仅需要团队所有成员认可,更重要的是需要老板的认可,没有老板的认可,稳定性建设工作只是团队内部的“小打小闹”,难以去跨团队来体系化运作稳定性建设工作的年度目标可以拿服务可用时长占比来定,也可以拿全年故障等级和次数来定重大事故,是需要消耗服务不可用时长的(根据全年定的服务可用时长占比指标来计算出某个部门的全年服务不可用总时长),一旦年底某个部门的全年服务不可用时长超过年初设定的阈值,就会有一定的处罚,并影响部门绩效这里做一个汇总:4. 稳定性建设四个方向前面我们提到的稳定性建设工作的四个关键点,但对如何落地阐述的并不多,这里结合作者多年的稳定性建设工作经验,谈谈稳定性建设工作的四个方向第一个方向:根基要抓牢(45%)稳定性建设工作重在预防,根据作者多年的工作经验,至少 6 成线上故障都可以在预防工作中消除,我们需要投入 45%的精力来做根基建设,所谓根基建设,就是把开发、测试、上线这三大流程做透
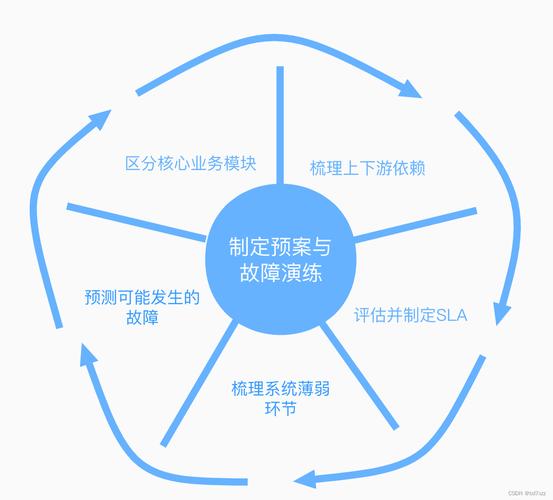
下面列了几个关键点:Code Review:CR 其实是一个很重要的环节,当一个开发整个编码和提测都可以自己闭环搞定时,时间一长就容易产生懈怠,这时候写隐患代码的几率会大大提高,CR 的过程并不是 diss 的过程,这个一定要在团队内拉齐,相反,CR 是一次很好的团队沟通和塑造自己影响力的机会CR 还可以让其他成员来检测该代码实现是否遵循了开发规范,毕竟“先污染后治理”的成本太高,记住,CR 一定是一个相互学习的过程设计评审:确保软件质量、提高开发效率、降低开发成本、提高团队协作能力和增强项目管理能力,对软件项目的成功至关重要软件质量:通过对软件设计进行评审,可以发现设计中的缺陷和问题,及时进行修改和完善开发效率:使开发人员更好地理解软件设计,减少开发过程中的误解和错误,从而提高开发效率开发成本:及时发现和解决设计中的问题,避免在开发后期进行大规模的修改和重构,从而降低开发成本协作能力:评审过程需要开发人员、测试人员、项目经理等多个角色参与,可以促进团队成员之间的交流和协作,提高团队的协作能力项目管理:通过评审,可以及时了解项目的进展情况,发现项目中的风险和问题,从而及时采取措施进行调整和管理,增强项目管理能力提测标准:写完代码就可以提测了?当然不是,至少得完成补充单元测试、完成自测、完成开发侧的联调、通过测试用例、补充改动点和影响点、补充设计文档这些步骤才能说可以提测了当然,提测标准理论上是 QA 同学来定义的测试流程:测试的全流程覆盖最好能做到全自动化,很多测试用例可以沉淀下来,用来做全流程回归,当然这需要系统支持我也见过太多犹豫 QA 没精力进行全流程回归而导致问题没有提前发现而产生的事故,所以 测试的原则是尽可能自动化和全流程覆盖,让宝贵的人力资源投入到只能人工测试的环节上线流程:上线也是一个风险很高的操作部署平台需要支持灰度发布、小流量发布,强制让开发在发布时观察线上大盘和日志,一旦有问题,能做到快速回滚(当然要关注回滚条件)建议做法是先小流量集群灰度,再线上灰度,确保哪怕出问题也能控制影响灰度流程不是绝对的,根据实际情况来进行抉择第二个方向:工作在日常(30%)人人参与:团队内人人都需要参与稳定性建设工作,稳定性工作不是某个人的事情,所以我会要求所有人的 OKR 中都有稳定性建设的部分稳定性已经成为了生活本身特殊情况可能需要24小时随时响应,例如:金融,民生,交通,医疗等重要项目,重要性是显而易见的持续完善监控告警:监控告警就是我们发现故障的“眼睛”和“耳朵”,随着业务的不断迭代,会有很多新接口需要添加监控,一些老的监控的阈值也需要不断调整(否则大量告警会让人麻木),所以监控告警是一个持续优化的过程及时消灭小隐患:平日发现的一些问题要及时消灭,很多线上事故在事前都有一定预兆,放任平时的一些小问题不管,到后面只会给未来埋上隐患跨团队联动:稳定性肯定不是一个团队的事情,一些降级方案可能涉及多个团队的工作,所以定期的跨团队的沟通会议是很有必要的,要大伙一起使劲才能把事情做好复盘机制:对出过的线上事故一定要及时的进行复盘,通过复盘来发现我们现有流程、机制是否有问题,让大伙不要踩重复的坑,并不断完善我们的紧急预案复盘虽然属于事后的行为,但很重要,我们需要通过复盘来看下次是否能预防此故障,或者是否能更快的定位和止损会议机制:稳定性周会、稳定性月会,我们通过各种定期的会议来总结一些阶段性进展和成果,拉齐大家认知,这也是大伙日常稳定性工作露出的一个机会,所以非常重要第三个方向:预案是关键(15%)我们通常都会忽视预案的作用,因为预案整理起来确实比较麻烦,预案也需要随着功能的迭代而不断更新,否则将很容易过时,而且预案在平日非故障期间也确实没有发挥作用的机会但我们不得不承认紧急预案相当重要,特别是当我们去定位和止损一个比较复杂的线上问题时我们需要在预案的制定和演练上投入 15%的精力,可以从如下三个方面着手:分场景制定和完善紧急预案:如果我们还没有紧急预案,那第一步就是分类分场景整理下历史上经常发生的线上事故,例如 MySQL 故障预案、MQ 故障预案、发单接口故障预案等而且预案有可能会被多人查看,一定要清晰易懂,如果某些预案是有损的,需要把副作用也描述清楚通过放火平台来验证预案:借助放火平台和服务降级系统,我们可以通过主动给主流程服务的非核心依赖注入故障,来验证系统在遇到非核心依赖发生故障时,核心服务是否仍旧有效,如果某些预案无法做成系统自动的(比如某些预案有一定的风险或副作用),也可以在预发环境来验证该预案是否能达到预期效果,防止真正故障发生时“手生”预案就是在这种不断演练过程中来优化和完善的,这样的预案才是动态的,才是活生生有效可靠的
第四个方向:容量是核心(10%)我们知道木桶效应,一个木桶能装多少水取决于最短的那块板,在分布式系统中也是如此,我们需要摸到分布式系统中的这块“短木板”才能知道整个系统的吞吐量(容量)?最准确的容量预估方案就是——线上全链路压测我们应该投入 10%的精力来摸容量、扩容量、水位预警等容量也相当重要,根据我的经验,线上有大约 10%的故障和容量有关,当遇到这种问题,最有效的解决方案就是扩容
关于容量,我们在日常需要做到如下三点:常态化的全链路压测:线上全链路压测必须定期举行,特别的在有大促活动时,也需要提前进行一次因为随着业务的快速迭代,系统老的瓶颈可能消失,新的瓶颈可能出现,所以之前的全链路压测的结果将失效,我们需要定期去摸这个线上环境的这个阈值定期进行扩容演练:会定期进行弹性云扩容演练,这在紧急情况下很有用,我们就曾经遇到过弹性云扩容比修改阈值重新上线更快解决问题的 case多活建设:我们知道多活主要是为了容灾,但其实多活实际上也从整体上增加了系统容量,所以也属于容量扩充的范畴,一旦某个机房遇到瓶颈,我们可以分流到其他机房当然多活建设需要一定成本,业务量大到一定程度才需要投入说了这么多,我们也放张图来进行总结:3. 总结稳定性是一个大投入,做稳定性建设一定要结合公司的实际情况,量入为出,最合适的方案才是最好的方案结合咱们上述讨论的几点,我们可以画出稳定性建设的房子,如下:本文参考:稳定性全系列(一):如何做好系统稳定性建设_移动_易振强_InfoQ精选文章


0 评论