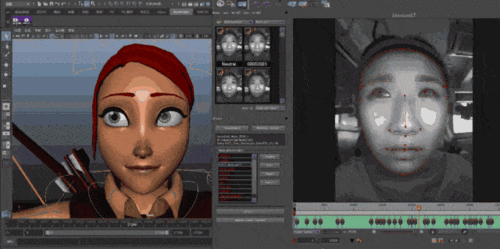
深圳商报•读创客户端记者 陈姝图生视频又有新玩法。腾讯混元联合港科大、清华大学联合推出肖像动画生成框架“Follow Your Emoji”,可以通过人脸骨架信息生成任意风格的脸部动画,一键创建“表情包”。基于算法革新和数据积累,“Follow Your Emoji”可以支持对脸部进行精细化的控制,包括眉毛,眼珠,翻白眼等细节,动物表情包也可以轻松“拿捏”。近年来,扩散模型展示了比旧的对抗式(GAN)方法更好的生成能力。一些方法利用强大的基础扩散模型进行高质量视频和图像生成, 但这些基础模型无法直接在动画过程中保留参考肖像的身份特征并有效地对肖像进行目标表情建模,导致视频结果显示出失真和不现实的伪影,特别是在动画化不常见领域肖像(如卡通、雕塑和动物)。这是肖像动画任务的主要挑战之一。本研究中,研究员提出了一个新颖的基于扩散模型的肖像动画框架Follow-Your-Emoji。算法上有两大主要创新。首先,引入了表情感知骨架这一表情控制信号,能够有效地引导动画生成。具体来看,研究员们通过肖像(面部)3D关键点来定位信息,由于3D关键点具有固有的规范属性,可以有效地将目标动作与参考肖像对齐,避免出现失真,导致生成的视频脸部变形。其次,该研究还提出了一种面部细粒度损失函数,以帮助模型专注于捕捉微妙的表情变化和参考照片中肖像的详细外观。具体地,作者首先利用面部掩模和表情掩模与作者的表情感知信号,然后计算这些掩模区域中地面真实值和预测结果之间的空间距离,来实现表情包对原肖像的高度还原。为了训练模型,本项研究还构建了一个高质量的表情训练数据集,其中包含18种夸张的表情和来自115位主体的20分钟真人视频。同时,研究采用了渐进式生成策略,使方法能够扩展到具有高保真度和稳定性的长期动画合成。为了解决肖像动画领域缺乏基准测试的问题,研究还引入了一个名为EmojiBench的综合基准测试,其中包括410个各种风格的肖像动画视频,展示了广泛的面部表情和头部姿势。使用EmojiBench对Follow-YourEmoji进行了全面评估,评估结果表明,本方法在处理训练领域之外的肖像和动作时表现出色,与现有的基准方法相比,本方法在定量和定性上均表现更好,提供了出色的视觉保真度身份表现和精确的动作渲染。








0 评论