
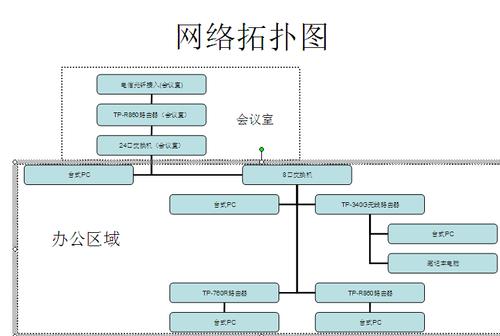
size_t send(int sockfd, const void buf, size_t len, int flags);我们需要使用eBPF,hook这些函数 找到对应的linux进程下sockfd 所对应的tcp五元组,然后进行汇总统计来绘制网络拓扑图3.对监控网络场景进行分析1)擎创采集器开启后建立的TCP连接擎创采集器启动后服务程序通过调用 listen 和 accept 函数,接收客户端的连接请求,并与客户端建立通信而对于客户端而言,通过调用 connect 函数来建立和服务程序的连接这些连接和之后的数据传输过程使用的系统调用,通过使用基于eBPF的技术,都可以eBPF嵌入字节码程序并进行分析2)擎创采集器开启前建立的TCP连接由于调用方和服务器的tcp 连接过程早已创建完成并不会再触发connect 和 accept的系统调用,只是在数据传输中调用send、recv或者write、read系列的函数如果应用程序之间数据传输使用的是write和read,并没有调用sockfd_lookup_light,所以暂时无法通过fd找到对应的sock 五元组但是如果应用程序之间的传输使用的是send和recv等系统调用,kernel 在内部会调sockfd_lookup_light,我们可以通过 pid 和fd的组合翻译出对应的sock五元组由于connect和accept在采集器启动之前已经建立连接,所以我们无法通过eBPF确认出流量的出入口方向例如go的一些应用程序:https://pkg.go.dev/net@go1.21.0#IPConn.ReadIPConn 只提供了Read和write接口,如果TCP连接在采集器启动之前已经建立了连接,我们暂时无法把fd翻译成TCP五元组,也无法确认流量方向4.通过linux源码分析系统调用1)找到hook点linux 内核中定义recvmsgSYSCALL_DEFINE3(recvmsg, int, fd, struct user_msghdr __user , msg, unsigned int, flags)内核整个调用过程SYSCALL_DEFINE3(recvmsg) -> __sys_recvmsg->sockfd_lookup_light->___sys_recvmsg通过解读recvmsg 我们发现 kernel 会在我们调用系统调用后通过sockfd_lookup_light把传进来的fd整数转化成为kernel的sock数据结构,即在给定的网络命名空间中查找并返回与指定文件描述符(socket 文件描述符)相对应的 struct socket 结构体指针,以便对套接字进行进一步的操作sockfd_lookup_light 使用的系统调用有:read 和 write 并没有使用 sockfd_lookup_light,统一把 read write 处理操作挂到了,文件描述符操作结构体上struct file_operations { struct module owner; ......... ssize_t (read) (struct file , char __user , size_t, loff_t ); ssize_t (write) (struct file , const char __user , size_t, loff_t ); ........} __randomize_layout;5.我们使用eBPF1)hook sockfd_lookup_light首先我们uprobe 住入口函数,记下进程号和 描述符的对应关系,因为每个进程的fd 都会对应一个sock结构体,所以我们把pid 进程号和 fd 组成一个keySEC("kprobe/sockfd_lookup_light")int kprobe_hook_sockfd_lookup_light(struct pt_regs ctx) { int sockfd = (int)PT_REGS_PARM1(ctx); u64 pid_tgid = bpf_get_current_pid_tgid(); pid_fd_map key = { .pid = pid_tgid >> 32, .fd = sockfd, }; struct sock sock = bpf_map_lookup_elem(&sock_by_pid_fd_storage, &key); if (sock != NULL) { return 0; } bpf_map_update_elem(&sockfd_save_args, &pid_tgid, &sockfd, BPF_ANY); return 0;}最后我们再 sockfd_lookup_light 把 pid和fd 的对应关系存储到mapSEC("kretprobe/sockfd_lookup_light")int kretprobe_hook_sockfd_lookup_light(struct pt_regs ctx) { u64 pid_tgid = bpf_get_current_pid_tgid(); int sockfd = bpf_map_lookup_elem(&sockfd_save_args, &pid_tgid); if (sockfd == NULL) { return 0; } struct socket socket = (struct socket )PT_REGS_RC(ctx); enum sock_type sock_type = 0; bpf_probe_read_kernel(&sock_type, sizeof(short), &socket->type); ................. // 读出sock 结构体 struct sock sock = NULL; bpf_core_read(&sock, sizeof(sock), (char )socket); pid_fd_map pid_fd = { .pid = pid_tgid >> 32, .fd = (sockfd), }; bpf_map_update_elem(pid_fd_by_sock, &sock, &pid_fd, BPF_ANY);cleanup: bpf_map_delete_elem(&sockfd_save_args, &pid_tgid);}每当内核触发sockfd_lookup_light的时候我们就会把 pid,fd 以及sock 对应关系存储到sockfd_save_args中socket 五元组多存储在linux 内核的 struct sock 中struct sock {....struct sock_common { union { __addrpair skc_addrpair; struct { __be32 skc_daddr; __be32 skc_rcv_saddr; }; }; union { unsigned int skc_hash; __u16 skc_u16hashes[2]; }; / skc_dport && skc_num must be grouped as well / union { __portpair skc_portpair; struct { __be16 skc_dport; __u16 skc_num; }; };}....}6.使用eBPF 绘制网络拓扑通过hook accept 标记处的入口流量SEC("kretprobe/inet_csk_accept")通过hook connect 标记处的出口流量SEC("kprobe/tcp_connect")SEC("kprobe/tcp_finish_connect")通过hook sockfd_lookup_light 翻译出进程的fd对应的sock五元组SEC("kretprobe/sockfd_lookup_light")程序在调用系统调用的时候,我们就很容易使用 通过pid fd,在eBPF的 sock_by_pid_fd_storage map中 找到对应的sock,找到了kernel sock 结构体我们就可以通过sock 五元组,绘制出流量方向绘制网络拓扑图的过程中,我们使用eBPF可以抓取网络数据包并对其进行解析,获取各个节点之间的连接信息,包括源地址、目标地址、协议类型、端口等通过收集和分析这些数据,我们可以逐步构建整个网络拓扑,并将其可视化为图形化的形式最后结合使用eBPF程序和图形数据库,我们完成了网络拓扑的绘制:以上即为本次eBPF绘制网络拓扑图的全部内容可观测之eBPF系列,正在不断创作中,欢迎您长期关注~如果有用,请辛苦点个赞吧擎创科技,Gartner连续推荐的AIOps领域标杆供应商公司专注于通过提升企业客户对运维数据的洞见能力,为运维降本增效,充分体现科技运维对业务运营的影响力行业龙头客户的共同选择了解更多运维干货与行业前沿动态可以右上角一键关注我们是深耕智能运维领域近十年的连续多年获Gartner推荐的AIOps标杆供应商下期我们不见不散~
(图片来源网络,侵删)



0 评论