\r\r\r\r\r
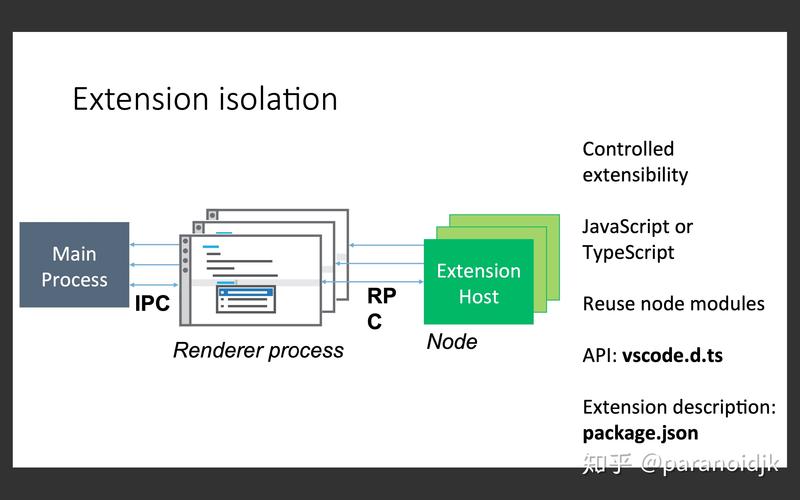
\r \r\r\r\r 第1章 CUDA介绍及入门\r\r 本章向你简要介绍CUDA架构以及它是如何重新定义GPU的并行处理能力应用软件如何使用CUDA架构?我们将演示一些实际的应用场景本章希望成为使用通用GPU和CUDA加速的软件入门指南本章描述了CUDA应用程序所使用的开发环境以及如何在各种操作系统上安装CUDA工具包它涵盖了如何在Windows和Ubuntu上使用CUDA C开发基本代码\r\r 本章将讨论以下主题:\r\r ·CUDA介绍\r\r ·CUDA应用\r\r ·CUDA开发环境\r\r ·在Windows、Linux和macOS上安装CUDA工具包\r\r ·使用CUDA C开发简单的代码\r\r 1.1 技术要求\r\r 本章要求熟悉基本的C或C++编程语言本章所有代码可以从GitHub链接https://github.com/PacktPublishing/Hands-On-GPU-Accelerated-Computer-Vision-with-OpenCV-and-CUDA下载尽管代码只在Windows 10和Ubuntu 16.04上测试过,但可以在任何操作系统上执行\r\r 1.2 CUDA介绍\r\r 计算统一设备架构(Compute Unified Device Architecture,CUDA)是由英伟达(NVIDIA)开发的一套非常流行的并行计算平台和编程模型它只支持NVIDIA GPU卡OpenCL则用来为其他类型的GPU编写并行代码,比如AMD和英特尔,但它比CUDA更复杂CUDA可以使用简单的编程API在图形处理单元(GPU)上创建大规模并行应用程序\r\r 使用C和C++的软件开发人员可以通过使用CUDA C或C++来利用GPU的强大性能来加速他们的软件应用程序用CUDA编写的程序类似于用简单的C或C++编写的程序,添加需要利用GPU并行性的关键字CUDA允许程序员指定CUDA代码的哪个部分在CPU上执行,哪个部分在GPU上执行\r\r 下一节将详细介绍并行计算的需求以及CUDA架构是如何利用GPU的强大性能\r\r 1.2.1 并行处理\r\r 近年来,消费者对手持设备的功能要求越来越高因此,有必要将越来越多的晶体管封装在一个小的电路板上,既能快速工作,又能耗电最少我们需要一个可以快速运行的处理器以较高的时钟速度、较小的体积和最小的功率执行多项任务在过去的几十年中,晶体管的尺寸逐渐减小,这就可以让越来越多的晶体管封装在一个芯片上,也导致了时钟速度的不断提高然而,这种情况已经发生了变化,最近几年时钟速度或多或少保持不变那么,原因是什么呢?难道是晶体管不再变小了吗?答案是否定的时钟速度恒定背后的主要原因是高功率损耗和高时钟速率小的晶体管在小面积内封装和高速工作将耗散大功率,因此它是很难保持处理器的低温开发中随着时钟速度逐渐饱和,我们需要一个新的计算模式来提高处理器性能让我们通过一个真实生活中的小例子来理解这个概念\r\r 假设你被告知要在很短的时间内挖一个很大的洞你会有以下三种方法以及时完成这项工作:\r\r ·你可以挖得更快\r\r ·你可以买一把更好的铲子\r\r ·你可以雇佣更多的挖掘机,它们可以帮助你完成工作\r\r 如果我们能在这个例子和一个计算模式之间找出关联,那么第一种选择类似于更快的时钟第二种选择类似于拥有更多可以在每个时钟周期做更多工作的晶体管但是,正如我们之前段落里讨论过的,功耗限制了这两个步骤第三种选择是类似于拥有许多可以并行执行任务的更小更简单的处理器GPU遵循这种计算模式它不是一个可以执行复杂任务的更强大的处理器,而是有许多小而简单的且可以并行工作的处理器下一节将解释GPU架构的细节\r\r 1.2.2 GPU架构和CUDA介绍\r\r GeForce 256是英伟达于1999年开发的第一个GPU最初只用在显示器上渲染高端图形它们只用于像素计算后来,人们意识到如果可以做像素计算,那么他们也可以做其他的数学计算现在,GPU除了用于渲染图形图像外,还用于其他许多应用程序中这些GPU被称为通用GPU(GPGPU)\r\r 你可能会想到的下一个问题是CPU和GPU的硬件架构有什么不同,从而可以使得GPU能够进行并行计算?CPU具有复杂的控制硬件和较少的数据计算硬件复杂的控制硬件在性能上提供了CPU的灵活性和一个简单的编程接口,但是就功耗而言,这是昂贵的而另一方面,GPU具有简单的控制硬件和更多的数据计算硬件,使其具有并行计算的能力这种结构使它更节能缺点是它有一个更严格的编程模型在GPU计算的早期,OpenGL和DirectX等图形API是与GPU交互的唯一方式对于不熟悉OpenGL或DirectX的普通程序员来说,这是一项复杂的任务这促成了CUDA编程架构的开发,它提供了一种与GPU交互的简单而高效的方式关于CUDA架构的更多细节将在下一节中给出\r\r 一般来说,任何硬件架构的性能都是根据延迟和吞吐量来度量的延迟是完成给定任务所花费的时间,而吞吐量是在给定时间内完成任务的数量这些概念并不矛盾通常情况下,提高一个,另一个也会随之提高在某种程度上,大多数硬件架构旨在提高延迟或吞吐量例如,假设你在邮局排队你的目标是在很短的时间内完成你的工作,所以你想要改进延迟,而坐在邮局窗口的员工想要在一天内看到越来越多的顾客因此,员工的目标是提高吞吐量在这种情况下,改进一个将导致另一个的改进,但是双方看待这个改进的方式是不同的\r\r 同样,正常的串行CPU被设计为优化延迟,而GPU被设计为优化吞吐量CPU被设计为在最短时间内执行所有指令,而GPU被设计为在给定时间内执行更多指令GPU的这种设计理念使它们在图像处理和计算机视觉应用中非常有用,这也是本书的目的,因为我们不介意单个像素处理的延迟我们想要的是在给定的时间内处理更多的像素,这可以在GPU上完成\r\r 综上所述,如果我们想在相同的时钟速度和功率要求下提高计算性能,那么并行计算就是我们所需要的GPU通过让许多简单的计算单元并行工作来提供这种能力现在,为了与GPU交互,并利用其并行计算能力,我们需要一个由CUDA提供的简单的并行编程架构\r\r 1.2.3 CUDA架构\r\r 本节介绍在GPU架构中如何进行基本的硬件修改,以及使用CUDA开发程序的一般结构我们暂时不讨论CUDA程序的语法,但是我们将讨论开发代码的步骤本节还将介绍一些基本的术语,这些术语将贯穿全书\r\r CUDA架构包括几个专门为GPU通用计算而设计的特性,这在早期的架构中是不存在的它包括一个unified shedder管道,它允许GPU芯片上的所有算术逻辑单元(ALU)被一个CUDA程序编组ALU还被设计成符合IEEE浮点单精度和双精度标准,因此它可以用于通用应用程序指令集也适合于一般用途的计算,而不是特定于像素计算它还允许对内存的任意读写访问这些特性使CUDA GPU架构在通用应用程序中非常有用\r\r 所有的GPU都有许多被称为核心(Core)的并行处理单元在硬件方面,这些核心被分为流处理器和流多处理器GPU有这些流多处理器的网格在软件方面,CUDA程序是作为一系列并行运行的多线程(Thread)来执行的每个线程都在不同的核心上执行可以将GPU看作多个块(Block)的组合,每个块可以执行多个线程每个块绑定到GPU上的不同流多处理器CUDA程序员不知道如何在块和流多处理器之间进行映射,但是调度器知道并完成映射来自同一块的线程可以相互通信GPU有一个分层的内存结构,处理一个块和多个块内线程之间的通信这将在接下来的章节中详细讨论\r\r 作为一名程序员,你会好奇CUDA中的编程模型是什么,以及代码将如何理解它是应该在CPU上执行还是在GPU上执行本书假设我们有一个由CPU和GPU组成的计算平台我们将CPU及其内存称为主机(Host),GPU及其内存称为设备(Device)CUDA代码包含主机和设备的代码主机代码由普通的C或C++编译器在CPU上编译,设备代码由GPU编译器在GPU上编译主机代码通过所谓的内核调用调用设备代码它将在设备上并行启动多个线程在设备上启动多少线程是由程序员来决定的\r\r 现在,你可能会问这个设备代码与普通C代码有何不同答案是,它类似于正常的串行C代码只是这段代码是在大量内核上并行执行的然而,要使这段代码工作,它需要设备显存上的数据因此,在启动线程之前,主机将数据从主机内存复制到设备显存线程处理来自设备显存的数据,并将结果存储在设备显存中最后,将这些数据复制回主机内存进行进一步处理综上所述,CUDA C程序的开发步骤如下:\r\r 1)为主机和设备显存中的数据分配内存\r\r 2)将数据从主机内存复制到设备显存\r\r 3)通过指定并行度来启动内核\r\r 4)所有线程完成后,将数据从设备显存复制回主机内存\r\r 5)释放主机和设备上使用的所有内存\r\r 1.3 CUDA应用程序\r\r CUDA在过去十年经历了前所未有的增长它被广泛应用于各个领域的各种应用中它改变了多个领域的研究在本节中,我们将研究其中的一些领域,以及CUDA如何加速每个领域的增长:\r\r ·计算机视觉应用:计算机视觉和图像处理算法是计算密集型的越来越多的摄像头在捕获高分辨率图像时,需要实时处理这些大图像随着这些算法实现CUDA加速,图像分割、目标检测和分类等应用可以实现超过30帧/秒的实时帧率性能CUDA和GPU允许对深度神经网络和其他深度学习算法进行更快的训练,这改变了计算机视觉的研究英伟达正在开发多个硬件平台,如Jetson TK1、Jetson TX1和Jetson TX2,这些平台可以加速计算机视觉应用英伟达drive平台也是为自动驾驶应用而设计的平台之一\r\r ·医学成像:在医学成像领域,GPU和CUDA被广泛应用于磁共振成像和CT图像的重建和处理这大大减少了这些图像的处理时间现在,带有GPU的设备,可以借助一些库来使用CUDA加速处理这些图像\r\r ·金融计算:所有金融公司都需要以更低的成本进行更好的数据分析,这将有助于做出明智的决策它包括复杂的风险计算及初始和寿命裕度计算,这些都必须实时进行GPU帮助金融公司在不增加太多间接成本的情况下,实时地做多种分析\r\r ·生命科学、生物信息学和计算化学:模拟DNA基因、测序和蛋白质对接是需要大量计算资源的计算密集型任务GPU有助于这种分析和模拟GPU可以运行普通的分子动力学、量子化学和蛋白质对接应用程序,比普通CPU快5倍以上\r\r ·天气研究和预报:与CPU相比,利用GPU和CUDA的几种天气预报应用、海洋建模技术和海啸预测技术可以进行更快的计算和模拟\r\r ·电子设计自动化(EDA):随着日益复杂的超大规模集成电路技术和半导体制造工艺的发展,使得EDA工具的性能在这一技术进步上落后它导致了模拟不完整和功能bug的遗漏因此,EDA行业一直在寻求更快的仿真解决方案GPU和CUDA加速正在帮助这个行业加速计算密集型EDA模拟,包括功能模拟、placement和rooting,以及信号完整性和电磁学、SPICE电路模拟等\r\r ·政府和国防:GPU和CUDA加速也被政府和军队广泛使用航空航天、国防和情报工业正在利用CUDA加速将大量数据转化为可操作的信息\r\r 1.4 CUDA开发环境\r\r 要开始使用CUDA开发应用程序,你需要为它配置开发环境为CUDA建立开发环境应具备以下先决条件:\r\r ·支持CUDA的GPU\r\r ·英伟达显卡驱动程序\r\r ·标准C编译器\r\r ·CUDA开发工具包\r\r 下面的几节将讨论如何检查第1个和第4个先决条件并安装它们\r\r 1.4.1 支持CUDA的GPU\r\r 如前所述,CUDA架构仅支持NVIDIA GPU它不支持其他GPU,如AMD和英特尔英伟达在过去十年中开发的几乎所有GPU都支持CUDA架构,可以用于开发和执行CUDA应用程序可以在英伟达网站上找到支持CUDA的GPU的详细列表,网址为:https://developer.nvidia.com/cuda-gpus如果你的GPU在列表里,那么你可以在你的PC上运行CUDA应用\r\r 如果你不知道你的PC上是哪个GPU,可以通过以下步骤找到它:\r\r 在Windows下:\r\r 1)在开始菜单中,输入设备管理器,然后按Enter键\r\r 2)在设备管理器中,单击显示适配器在那里,你会找到你的NVIDIA GPU的名称\r\r 在Linux下:\r\r 1)打开Terminal\r\r 2)运行sudo lshw-C video\r\r 这将列出有关显卡的信息,通常包括它的制造商和型号\r\r 在macOS下:\r\r 1)到苹果菜单|关于这个Mac|更多信息\r\r 2)在内容列表下选择图形/显示在那里,你会找到你的NVIDIA GPU的名称\r\r 如果你有一个支持CUDA的GPU,那么你可以继续下一步\r\r 1.4.2 CUDA开发工具包\r\r CUDA需要一个GPU编译器来编译GPU代码这个编译器附带一个CUDA开发工具包如果你有一个最新驱动程序更新的NVIDIA GPU,并且为你的操作系统安装了一个标准的C编译器,那么你可以进入安装CUDA开发工具包的最后一步下一节将讨论安装CUDA开发工具包的步骤\r\r 1.5 在所有操作系统上安装CUDA工具包\r\r 本节介绍了如何在所有支持平台安装CUDA工具包,以及如何验证是否安装成功\r\r 安装CUDA时,可以选择下载在线安装器或离线本地安装器前者需要手工下载的大小比较小,但是安装时需要连接互联网后者一次性下载完成后虽然较大,但是安装时不需要连接互联网可以从https://developer.nvidia.com/cuda-downloads下载适合Windows、Linux以及macOS的安装包注意曾经有两种CUDA开发包(32位和64位),但现在NVIDIA已经放弃对32位版本的支持,因此你只能安装64位版本的注意下面我们用CUDAx.x代表你实际下载到的CUDA工具包版本\r\r 本书选择后者\r\r 1.5.1 Windows\r\r 本节介绍在Windows上安装CUDA的步骤,如下所示:\r\r 1)双击安装程序它将要求你选择将提取临时安装文件的文件夹选择你选择的文件夹建议将此作为默认值\r\r 2)然后,安装程序将检查系统兼容性如果你的系统兼容,则可以按照屏幕提示安装CUDA你可以选择快速安装(默认)和自定义安装自定义安装允许选择要安装的CUDA功能建议选择快速安装\r\r 3)安装程序还将安装CUDA示例程序和CUDA Visual Studio集成\r\r 在运行之前,请确保已安装Visual Studio安装程序\r\r 1.5.2 Linux\r\r 本节介绍了如何在Linux发行版上安装CUDA开发包Ubuntu是一种很流行的Linux发行版具体的安装过程,将分别讨论使用NV提供的针对特定(Ubuntu)发行版的安装包和使用Ubuntu特定的apt-get命令这两种方式\r\r 从前面的CUDA页面下载.deb安装程序,然后按以下具体步骤安装:\r\r 1)打开终端并运行dpkg命令,该命令用于在基于Debian的系统中安装包:\r\r \r\r 2)使用以下命令安装CUDA公共GPG密钥:\r\r \r\r 3)使用以下命令更新apt repository缓存:\r\r \r\r 4)使用以下命令安装CUDA:\r\r \r\r 5)用下面的命令修改PATH环境变量,以包含CUDA安装路径的bin目录:\r\r \r\r 如果你没有在默认位置安装CUDA,则用你的实际安装目录代替这里的例子\r\r 6)通过这行命令设定LD_LIBRARY_PATH环境变量,来设定库搜索目录:\r\r \r\r 此外,你还可以通过第二种方式来安装CUDA开发包,也就是使用Ubuntu自带的apt-get在命令行终端里输入如下命令即可:\r\r \r\r 7)nvcc将分别编译.cu文件中的Host和Device代码,前者是通过系统自带的GCC之类的Host代码编译器进行的,而后者则是通过CUDA C前端等一系列工具进行你可以通过如下命令安装NSight Eclipse Edition(这也是NV的叫法),用作Linux下开发CUDA程序的图形化IDE环境\r\r \r\r 安装后,你可以在用户Home目录下面,编译并执行~/NVIDIA_CUDA-x.x_Samples/下面的deviceQuery例子如果你的CUDA开发包安装和配置正确的话,成功编译并运行后,你应当看到类似如图1-1所示的输出\r\r \r\r 图 1-1\r\r 1.5.3 Mac\r\r 本节介绍在macOS上安装CUDA的步骤从CUDA网站下载.dmg安装程序下载安装程序后安装的步骤如下:\r\r 1)启动安装程序并按照屏幕提示完成安装它将安装所有预制件、CUDA、工具包和CUDA示例\r\r 2)需要使用以下命令设置环境变量:\r\r \r\r 如果你没有在默认位置安装CUDA,则需要更改指向安装位置的路径\r\r 3)运行脚本:cuda-install-samples-x.x.sh它将安装具有写权限的CUDA示例\r\r 4)完成之后,可以转到bin/x86_64/darwin/release并运行deviceQuery程序如果CUDA工具包安装和配置正确,它将显示您的GPU的设备属性\r\r 1.6 一个基本的CUDA C程序\r\r 在本节中,我们将通过使用CUDA C编写一个非常基础的程序来学习CUDA编程我们将从编写一个“Hello,CUDA!”开始,在CUDA C中编程并执行它在详细介绍代码之前,有一件事你应该记得,主机代码是由标准C编译器编译的,设备代码是由NVIDIA GPU编译器来执行NVIDIA工具将主机代码提供给标准的C编译器,例如Windows的Visual Studio和Ubuntu的GCC编译器,并使用macOS执行同样需要注意的是,GPU编译器可以在没有任何设备代码的情况下运行CUDA代码所有CUDA代码必须保存为.cu扩展名\r\r 下面就是Hello,CUDA!的代码\r\r \r\r 如果你仔细查看代码,它看起来将非常类似于简单地用C语言编写的Hello,CUDA!用于CPU执行的程序这段代码的功能也类似它只在终端或命令行上打印“Hello,CUDA!”因此,你应该想到两个问题:这段代码有何不同?CUDA C在这段代码中扮演何种角色?这些问题的答案可以通过仔细查看代码来给出它与用简单的C编写的代码相比,有两个主要区别:\r\r ·一个名为myfirstkernel的空函数,前缀为__global__\r\r ·使用1,1调用myfirstkernel函数\r\r __global__是CUDA C在标准C中添加的一个限定符,它告诉编译器在这个限定符后面的函数定义应该在设备上而不是在主机上运行在前面的代码中,myfirstkernel将运行在设备上而不是主机上,但是,在这段代码中,它是空的\r\r 那么,main函数将在哪里运行?NVCC编译器将把这个函数提供给C编译器,因为它没有被global关键字修饰,因此main函数将在主机上运行\r\r 代码中的第二个不同之处在于对空的myfirstkernel函数的调用带有一些尖括号和数值这是一个CUDA C技巧:从主机代码调用设备代码它被称为内核调用内核调用的细节将在后面的章节中解释尖括号内的值表示我们希望在运行时从主机传递给设备的参数基本上,它表示块的数量和将在设备上并行运行的线程数因此,在这段代码中,1,1表示myfirstkernel将运行在设备上的一个块和一个线程或块上虽然这不是对设备资源的最佳使用,但是理解在主机上执行的代码和在设备上执行的代码之间的区别是一个很好的起点\r\r 让我们再来重温和修改“Hello,CUDA!”代码,myfirstkernel函数将运行在一个只有一个块和一个线程或块的设备上它将通过一个称为内核启动的方法从main函数内部的主机代码启动\r\r 在编写代码之后,你将如何执行此代码并查看输出?下一节将描述在Windows和Ubuntu上编写和执行Hello CUDA!代码的步骤
\r\r 1.6.1 在Windows上创建CUDA C程序的步骤\r\r 本节描述使用Visual Studio在Windows上创建和执行基本CUDA C程序的步骤步骤如下:\r\r 1)打开Microsoft Visual Studio\r\r 2)进入File|New|Project\r\r 3)依次选择NVIDIA|CUDA 9.0|CUDA 9.0 Runtime\r\r 4)为项目自定义名称,然后单击OK按钮\r\r 5)它将创建一个带有kernel.cu示例文件的项目现在双击打开这个文件\r\r 6)从文件中删除现有代码,写入前面编写的那段代码\r\r 7)从生成(Build)选项卡中选择生成(build)进行编译,并按快捷键Ctrl+F5调试代码如果一切正常,你会看到Hello,CUDA!显示在命令行上,如图1-2所示\r\r \r\r 图 1-2\r\r 1.6.2 在Ubuntu上创建CUDA C程序的步骤\r\r 本节描述使用Nsight Eclipse插件在Ubuntu上创建和执行基本CUDA C程序的步骤步骤如下:\r\r 1)打开终端并输入nsight来打开Nsight\r\r 2)依次选择File|New|CUDA C/C++Projects\r\r 3)为项目自定义名称,然后单击OK按钮\r\r 4)它将创建一个带有示例文件的项目现在双击打开这个文件\r\r 5)从文件中删除现有代码,写入前面编写的那段代码\r\r 6)按下play按钮运行代码如果一切正常,你会看到Hello,CUDA!显示在终端,如图1-3所示\r\r \r\r 图 1-3\r\r 1.7 总结\r\r 在这一章中,我介绍了CUDA,并简要介绍了并行计算的重要性我们还详细讨论了CUDA和GPU在各个领域的应用本章描述了在PC上执行CUDA应用程序所需的硬件和软件设置我们给出了在本地PC上安装CUDA的详细步骤\r\r 1.6节通过开发一个简单的程序并在Windows和Ubuntu上执行,给出了CUDA C中的应用程序开发的入门指南\r\r 在下一章中,我们将基于CUDA C中的编程知识,通过几个实际示例介绍使用CUDA C的并行计算,以展示它如何比普通编程更快还将介绍线程和块的概念,以及如何在多线程和块之间执行同步\r\r 1.8 测验题\r\r 1.解释三种提高计算硬件性能的方法使用哪种方法开发GPU?\r\r 2.真假判断:改进延迟将提高吞吐量\r\r 3.填空:CPU被设计用来改进____,GPU被设计用来改进___\r\r 4.举个例子,从一个地方到240公里以外的另一个地方你可以开一辆能容纳5人的车,时速60公里,或者开一辆能容纳40人的公交车,时速40公里哪个选项将提供更好的延迟,哪个选项将提供更好的吞吐量?\r\r 5.解释GPU和CUDA在计算机视觉应用中特别有用的原因\r\r 6.真假判断:CUDA编译器不能在没有设备代码的情况下编译代码\r\r 7.在本章讨论的“Hello,CUDA!”例子中,printf语句是由主机执行还是由设备执行的?\r\r\r








0 评论