
public static void main(String[] args) throws MalformedURLException, IOException { //jericho官网URL String url = "http://jericho.htmlparser.net/docs/index.html"; Source source = new Source(new URL(url)); //获取HTML文档encoding属性 String encoding = source.getEncoding(); System.out.println(encoding); //获取HTML文档第一个标签元素 Element firstElement = source.getFirstElement(); System.out.println(firstElement); //获取所有的<H2>标签元素 List<Element> elements = source.getAllElements(HTMLElementName.H2); System.out.println(elements); //从HTML标记中提取所有文本 Element firstP = source.getFirstElement(HTMLElementName.P); System.out.println("输出标签中的全部文本内容:" + firstP.getTextExtractor()); //获取文档中第一个DIV标签 StartTag tagDiv = source.getFirstStartTag(HTMLElementName.DIV); //获取属性tagDiv标记的属性 Attributes attributes = tagDiv.getAttributes(); System.out.println("输出标签中的全部属性:" + attributes); //输出属性名、属性值 for (Attribute attr : attributes) { System.out.println("输出标签中的属性键值:" + attr.getName() + " ===> " + attr.getValue()); } //属性替换 Map<String, String> attributesMap = new HashMap<String, String>(); attributesMap.put("font-size", "12pt"); attributesMap.put("style", "background-color:red;width:200px;height:200px"); OutputDocument output = new OutputDocument(tagDiv); System.out.println("替换前:" + output.toString()); output.replace(attributes, attributesMap); System.out.println("替换后:" + output.toString()); //缩进,格式化HTML源文件 String text = "<table><tr><td></td></tr><tr><td></td></tr></table>"; Source textSource = new Source(text); String formatText = textSource.getSourceFormatter().toString(); System.out.println("缩进后的内容:"); System.out.println(formatText); //去掉空格 SourceCompactor restoreText = new SourceCompactor(new Segment(new Source(formatText), 0, formatText.length())); System.out.println("HTML压缩后:" + restoreText);}输出如下:UTF-8<?xml version="1.0" encoding="UTF-8"?>[<h2>Features</h2>, <h2>Sample Programs</h2>, <h2>Building</h2>, <h2>Alternative HTML Parsers</h2>]输出标签中的全部文本内容:Jericho HTML Parser is a java library allowing analysis and manipulation of parts of an HTML document, including server-side tags, while reproducing verbatim any unrecognised or invalid HTML. It also provides high-level HTML form manipulation functions.输出标签中的全部属性: style="float: right; margin-left: 20px"输出标签中的属性键值:style ===> float: right; margin-left: 20px替换前:<div style="float: right; margin-left: 20px">替换后:<div font-size="12pt" style="background-color:red;width:200px;height:200px">缩进后的内容:<table><tr><td></td></tr><tr><td></td></tr></table>HTML压缩后:<table><tr><td></td></tr><tr><td></td></tr></table>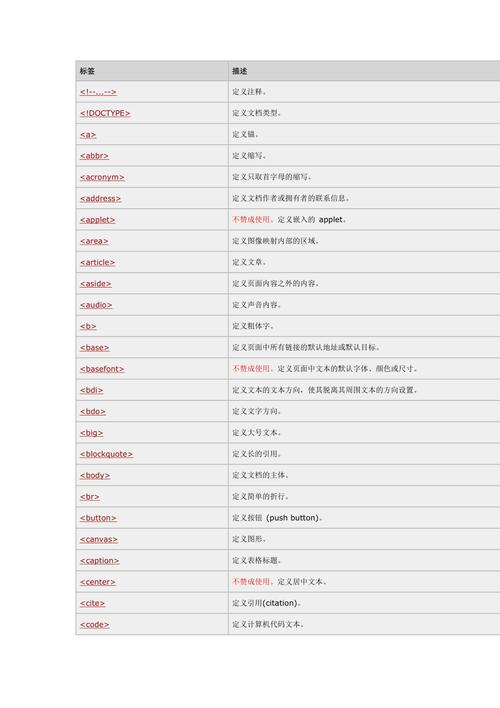
(图片来源网络,侵删)






0 评论