- APP神圣官网 > 软件快讯 > 正文
画像用户大揭秘minAIChatGPT(画像用户大揭秘产品模式)「用户画像 软件」
大家好,我是产品经理舟小鲤,目前正在探索 AI 如何提升我们日常产品设计工作的效率,例如利用 prompt 封装一些产品设计技能,让 AI 帮我们打工比如,让 AI 生成一份用户画像?用户画像可是帮助我们洞悉用户、进行产品设计的好工具大家是否有过需要了解新业务、挖掘一些新机会,但对业务和用户都一脸懵的情况?此时的你,一定想快速了解新业务的用户画像,但自己绘制用户画像可真是一件费时费力的活儿~获取用户画像的前期分析、调研工作,需要耗费大量时间和精力那么,想要快速拥有一份用户画像,🤖 AI 可以给到我们帮助吗?C 端和 B 端的用户画像都能搞定吗?AI 应该能够基于其训练过的大量语料,通过预测给出一些通用的用户群体特征带着这个想法,我尝试利用ChatGPT/NewBing + Midjourney,分别帮我生成用户画像的文本部分和用户形象图部分,再放进预制好的模板中,帮我们搞定用户画像
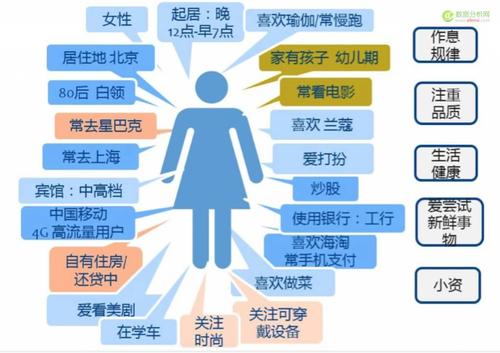
先来看看效果吧~例如,一个使用C 端打车软件的用户画像看下图,用户是年轻白领、使用场景是日常上下班、痛点是早晚高峰时段打出租车难B 端产品的朋友们别走,我也编写了适用于 B 端的用户画像分析的 prompt我们询问一下连锁餐饮店店长的用户画像,来看下效果:店长的痛点是员工管理难和库存信息不准确等等 ~不卖关子了,下面我将为大家详细说明,用 AI 快速生成 C 端和 B 端用户画像的方法
一、如何利用 AI 生成用户画像文本1. 用户画像文本生成- AI 工具选择本文,我们将使用 ChatGPT 和 NewBing(目前已经更名为 Microsoft Copilot ) ,来生成用户画像分析的文本选择了 NewBing 的原因,主要是 NewBing 能免费联网搜索,且能给出资料的出处,在我们本身没有收集到足够多信息的时候,可能可以给出更具有说服力和可信度的用户画像(备注:实测“创造力”模式的理解本 prompt 的能力更好)图:Bing 直接开启联网搜索,并提供了资料出处而对于 ChatGPT ,GPT-3.5 版本无法联网,但可以基于它的训练数据,给出预测的用户画像的答案想要联网,需要我们升级到 GPT-4 版本然后,GPT-4 并不会在每一次回答中都开启联网功能,你需要一些触发词指示GPT-4 联网,第一次我询问 2023 年发生的事件,GPT-4 主动联网搜索了答案(有 browsing 图标),第二次我询问中秋送什么礼物好,对于这类常识性的问题,GPT-4 则没有主动联网因此,我们可以直接输入“搜索”的指令,让 GPT-4 强制联网搜索2. 结构化 prompt 封装用户画像分析能力学习 prompt 期间,我最大的一个启发就是,我们可以把工作中需要的能力,封装成 prompt 的形式,并指定格式要求,让 AI 输出我们需要的内容如果我们需要封装的能力比较复杂,那么随手一写的 prompt 可能缺乏系统性,得到的答案也参差不齐我们可以利用 BROKE、ICIO 等 prompt 框架,或者结构化 prompt(详情请见文末参考),来更好地组织我们的编写语言,得到更好且更稳定的效果本文中,我会用到结构化 prompt 来封装用户画像分析的能力,接下来我将进行详细阐述我的需求分析步骤与 prompt 编写思路1)需求分析需求分析的方法有许多,针对这个小需求,我们可以进行一个简单的拆解,利用场景分析法,然后分析解法利用场景分析的好处,是可以更好地让我们自己,带入为需求的提出者,清晰地分析需求产生的原因、背景以下是我的分析思维导图:通过上述的分析,我们可以获得几个要点,在接下来的 prompt 编写过程中需要考虑:因为我们一般把和 AI 交互的人称为用户,但本 prompt 中我们又需要生成用户画像,所以可以在 prompt 中规定两个角色,避免 AI 产生误解本文将会把与 AI 对话的人称为“使用者”因为我们的场景是要研究一个新领域,非常不确定使用者手中有没有现成的用户资料,有多少资料,因此需要根据输入情况的不同,分别设计交互模式输出的用户画像,需要适配 C 端、B 端业务,可以分别设计 prompt为提升 AI 生成用户画像的准确度,可以先让 AI 生成简略版本,让用户对结果进行反馈,然后再生成详细的画像2)确定用户画像输出模板根据刚刚的需求分析,我们发现输出的用户画像,需要适配 C 端、B 端业务而 C 端 和 B 端的面向的用户、业务模式大有不同,因此 C 端 和 B 端用户画像分析的要点也随之发生变化(简单来说,我们平时买东西的淘宝是 C 端产品,淘宝给商家的应用软件是 B 端产品)而且,对于 B 端而言,用户的角色其实有两种,一种是企业,一种是企业中的工作者,那么会有两个用户画像:① 企业用户画像 和 ②职业用户画像我参考了「酷家乐用户体验设计团队」和「核糖 Bro」两位老师的用户画像分析文章(见文末参考),归纳出了 C 端和 B 端用户画像的模板,如下所示:(1)C 端用户画像模板基本信息:年龄、性别、城市、职业、收入水平、学历、家庭状况用户故事:用户和使用产品相关的背景故事,包括工作描述、生活习惯描述、兴趣爱好目标和需求:使用产品的目的、希望从产品中获得的价值行为模式:使用场景、使用频率、使用平台偏好、首选功能、时间和地点等用户痛点:痛点包括用户需求中的痛点、使用产品时可能遇到的困难情感态度:对产品的感受、喜好和不满意之处(2)B 端企业画像模板基本信息:公司名称、行业类别、企业规模(员工人数、年收入)、地理位置组织架构:企业自上而下的组织架构关键角色:组织中包含哪些岗位业务信息:业务概述、经营方式业务需求与痛点:当前业务场景的需求、核心痛点、现有解决方案的不足、期望的功能(3)B 端职业用户画像模板岗位名称:具体岗位名称;工作概览:公司名称、行业类别、岗位介绍、岗位职责基本信息:年龄、性别、城市、职业、收入水平、学历、家庭状况、入职时长行为模式:使用场景、使用地点、使用平台偏好、使用频率、 使用时间、使用时长需求与痛点:用户工作中的主要需求、核心痛点、现有解决方案的不足、期望的功能备注:以上只是小鲤的模板,大家可以根据自己的分析需要,替换模板的内容3)prompt 编写思路与结果本小节我将以“B 端产品-职业用户画像专家” prompt 为例,用一张思维导图和注释,为大家解释我的 prompt 编写思路话不多说,请见下图:我考虑的一些 tips:(1)注意考虑使用者的用户体验在整个流程中,需要注意添加引导语,让使用者可以了解需要回答什么信息,预知下一步会发生什么同时不要一次性询问过多问题,除非使用者主动要求一次性给出资料因此我设计了 3 种模式模式 2 为分步询问问题,为简化 prompt,分布询问的问题,也可以设计为让 AI 自动生成但经过我多次测试,AI 自动生成的问题可能会不稳定,所以在我的 prompt 中,我还是自己编写了 4 个引导提问(2)prompt 需要进行多轮测试,测试 prompt 时,如果发现 AI 回答模糊的信息,我们可以指定描述规则,例如:AI 在输出基本信息时,经常会出现不限的回答,可以要求 AI 必须推测一个答案AI 对使用场景的描述不够具体,可以定义具体的描述方法AI 对使用平台偏好的判断比较模糊,可以告诉 AI 一般的判断经验需求与痛点是一一对应的,可以设置以表格的形式输出这部分内容,让信息更加清晰(3)如果直接在可以联网的 ChatGPT 4 或 NewBing 上使用,可以加入联网技能,简化 prompt,只保留模式 1,依靠 AI 联网搜索整合所有需要的信息3. 用户画像 prompt最后,完整版的 “B 端产品-职业用户画像专家” prompt 如下:(C 端用户画像、B 端职业用户画像、B 端企业用户画像这三种用户画像的详细 prompt 和 对话效果,大家可以查看文末链接(本文资料合集))1)通用版本,没有联网指令,所有 AI 大模型可用( prompt 请查看文末链接)2)联网版本:加入联网指令,仅保留模式 1,适用于开启联网的 ChatGPT 4 和 NewBing( prompt 请查看文末链接)三种用户画像的详细 prompt 和 对话效果,大家可以查看文末链接(本文资料合集)在下一小节,我将为大家展示 prompt 的效果二、AI 分析效果大揭秘分析了这么多,prompt 的效果怎么样呢?本小节我将主要给大家展示“B 端产品-职业用户画像专家” prompt,在 ChatGPT 4 和 NewBing 上的的效果为了让大家更好地带入 prompt 使用者的身份,我们一起来假设一个场景:你是一家 SaaS 软件公司的产品经理,为了拓展业务的第二曲线,你们想研究一个新方向:餐饮行业的线上化解决方案因此,你想先了解下餐饮行业从业者的职业画像于是,你输入了 “B 端产品-职业用户画像专家” prompt1. 与 ChatGPT 的交互效果一开始,ChatGPT 会进行自我介绍,并简单介绍用户画像会包含哪些内容然后,开始询问我们第一个问题,要分析的用户画像目标是啥?我们可以回复,需要了解下“中式快餐连锁店,店长”的用户画像接下来 ChatGPT 会向我们介绍 3 种交互模式,并询问我们想要选择哪一种模式我们先来看看模式 1 的效果,对话链接请见:https://chat.openai.com/share/8025e884-9778-480b-b81a-03e455f8ec4a选择模式 1 后,ChatGPT 会按照指令为我们生成 3 个用户画像,并表示我们可以给出反馈,之后会在生成一个更详细的用户画像接着我们选择“店长 1”的画像,如果想触发 ChatGPT 的联网技能,我们也可以再输入“搜索”的指令,让 ChatGPT 基于互联网结果综合给我们一个答案收到指令后,ChatGPT 将开启联网搜索接下来,我们来看简单看下模式 2 的交互效果ChatGPT 会引导我们给出必要的信息,对于每个问题,Chat 会根据经验给出示例回答,让我们方便地选择我们也可以从招聘网站上搜集一些信息,给它分析对话链接请见:https://chat.openai.com/share/898f2619-1086-4ad5-9532-77111a48fafc最后,我们来看模式 3 的交互效果这种模式适合手中已经有一定资料的用户对话链接请见:https://chat.openai.com/share/5787e21a-f26c-44cd-821d-81953e5c13a4(左图:ChatGPT 的提问,右图:我回复的从招聘网站上找的信息)2. 与 NewBing 的交互效果我们开启 NewBing 的“创造力”模式,输入通用版的 promptNewBing 也能识别到 workflows 中我们设定的交互流程,并搜索互联网的数据,先给我们 3 个简单的用户画像然后,再根据我们的反馈,生成一个更详细的用户画像但测试中我发现,有几次 NewBing 的答案会偏离我们设定的“OutputFormat”,我们可以删除“initialization”部分,直接在最后指明需要生成的用户画像,这样 NewBing 就能够按照既定的格式输出有了文本,接下来,我将会和大家一起探索,如何利用 Midjourney(以下简称 MJ)生成用户的形象图,不管是真人形象,还是卡通形象,MJ 都能帮你搞定
资料参考OpenAI GPT 商店应用扣子 Coze 平台应用:国内无需魔法可用-扣子平台(Moonshot 模型) C端产品-用户画像专家 https://www.coze.cn/s/ijCdhhnr/B端产品-用户画像专家 https://www.coze.cn/s/ijC86s6c/Coze平台(GPT 4 模型) C端产品-用户画像专家 https://www.coze.com/s/ZmFqnTNAB/B端产品-用户画像专家 https://www.coze.com/s/ZmFqWLYAe/参考文章:作者:舟小鲤 微信公众号:舟小鲤本文由 @舟小鲤 原创发布于人人都是产品经理未经作者许可,禁止转载题图来自Unsplash,基于CC0协议该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务
联系我们
在线咨询:







0 评论