
其实是在贵阳花溪区吧\"sents = SentenceSplitter.split(text) print('\n'.join(sents))中文分句的输出结果如下所示:贵州财经大学要举办大数据比赛吗?那让欧几里得去问问看吧
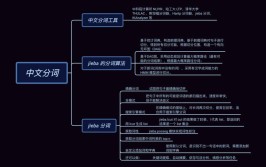
其实是在贵阳花溪区吧2.中文分词# -- coding: utf-8 --from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizertext = \"贵州财经大学要举办大数据比赛吗?那让欧几里得去问问看吧
其实是在贵阳花溪区吧\"#中文分词segmentor = Segmentor #初始化实例segmentor.load(\"AgriKG\\ltp\\cws.model\") #加载模型words = segmentor.segment(text) #分词print(type(words))print(' '.join(words))segmentor.release #释放模型输出结果如下所示(人工换行):<class 'pyltp.VectorOfString'>贵州 财经 大学 要 举办 大 数据 比赛 吗 ? 那 让 欧 几 里 得 去 问问 看 吧
其实 是 在 贵阳 花溪区 吧 此时的分词效果并不理想,如 “大数据” 分为了“大”、“数据”,“欧几里得”分为了“欧”、“几”、“里”、“得”,“贵阳花溪区”分为了“贵阳”、“花溪区”等,故需要引入词典进行更为准确的分词同时,返回值类型是native的VectorOfString类型,可以使用list转换成Python的列表类型3.导入词典中文分词pyltp 分词支持用户使用自定义词典分词外部词典本身是一个文本文件(plain text),每行指定一个词,编码同样须为 UTF-8,比如“word”文件,如下图所示:完整代码如下所示:# -- coding: utf-8 --from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizerldir='AgriKG\\ltp\\cws.model' #分词模型dicdir='word' #外部字典text = \"贵州财经大学要举办大数据比赛吗?那让欧几里得去问问看吧
其实是在贵阳花溪区吧\"#中文分词segmentor = Segmentor #初始化实例segmentor.load_with_lexicon(ldir, 'word') #加载模型words = segmentor.segment(text) #分词print(' '.join(words)) #分词拼接words = list(words) #转换listprint(u\"分词:\", words)segmentor.release #释放模型输出结果如下所示,它将“大数据”、“欧几里得”、“贵阳花溪区”进行了词典匹配,再进行相关分词,但是“贵州财经大学”仍然划分为“贵州”、“财经”、“大学”Why?贵州 财经 大学 要 举办 大数据 比赛 吗 ? 那 让 欧几里得 去 问问 看 吧
其实 是 在 贵阳花溪区 吧 分词: ['贵州', '财经', '大学', '要', '举办', '大数据', '比赛', '吗', '?', '那', '让', '欧几里得', '去', '问问', '看', '吧', '
', '其实', '是', '在', '贵阳花溪区', '吧', '']4.个性化分词个性化分词是 LTP 的特色功能个性化分词为了解决测试数据切换到如小说、财经等不同于新闻领域的领域在切换到新领域时,用户只需要标注少量数据个性化分词会在原有新闻数据基础之上进行增量训练从而达到即利用新闻领域的丰富数据,又兼顾目标领域特殊性的目的pyltp 支持使用用户训练好的个性化模型关于个性化模型的训练需使用 LTP,详细介绍和训练方法请参考 个性化分词 在 pyltp 中使用个性化分词模型的示例如下:# -- coding: utf-8 --from pyltp import CustomizedSegmentorcustomized_segmentor = CustomizedSegmentor #初始化实例customized_segmentor.load('基本模型', '个性模型') #加载模型words = customized_segmentor.segment('亚硝酸盐是一种化学物质')print '\t'.join(words)customized_segmentor.release词性标注词性标注(Part-Of-Speech tagging, POS tagging)也被称为语法标注(grammatical tagging)或词类消疑(word-category disambiguation),是语料库语言学(corpus linguistics)中将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术pyltp词性标注与分词模块相同,将词性标注任务建模为基于词的序列标注问题对于输入句子的词序列,模型给句子中的每个词标注一个标识词边界的标记在LTP中,采用的北大标注集完整代码:# -- coding: utf-8 --from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizerldir='AgriKG\\ltp\\cws.model' #分词模型dicdir='word' #外部字典text = \"贵州财经大学要举办大数据比赛吗?\"#中文分词segmentor = Segmentor #初始化实例segmentor.load_with_lexicon(ldir, 'word') #加载模型words = segmentor.segment(text) #分词print(text)print(' '.join(words)) #分词拼接words = list(words) #转换listprint(u\"分词:\", words)segmentor.release #释放模型#词性标注pdir='AgriKG\\ltp\\pos.model'pos = Postagger #初始化实例pos.load(pdir) #加载模型postags = pos.postag(words) #词性标注postags = list(postags)print(u\"词性:\", postags)pos.release #释放模型data = {\"words\": words, \"tags\": postags}print(data)输出结果如下图所示,“贵州”词性为“ns”(地理名词 ),“财经”词性为“n”(一般名词),“举办”词性为“v”(动词),“吗”词性为“u”(助词),“?”词性为“wp”(标点)贵州财经大学要举办大数据比赛吗?贵州 财经 大学 要 举办 大数据 比赛 吗 ?分词: ['贵州', '财经', '大学', '要', '举办', '大数据', '比赛', '吗', '?']词性: ['ns', 'n', 'n', 'v', 'v', 'n', 'v', 'u', 'wp']{'words': ['贵州', '财经', '大学', '要', '举办', '大数据', '比赛', '吗', '?'], 'tags': ['ns', 'n', 'n', 'v', 'v', 'n', 'v', 'u', 'wp']}具体词性为:Tag Description Examplea adjective:形容词 美丽 b other noun-modifier:其他的修饰名词 大型, 西式 c conjunction:连词 和, 虽然 d adverb:副词 很 e exclamation:感叹词 哎 g morpheme 茨, 甥 h prefix:前缀 阿, 伪 i idiom:成语 百花齐放 j abbreviation:缩写 公检法 k suffix:后缀 界, 率 m number:数字 一, 第一 n general noun:一般名词 苹果 nd direction noun:方向名词 右侧 nh person name:人名 杜甫, 汤姆 ni organization name:公司名 保险公司,中国银行nl location noun:地点名词 城郊ns geographical name:地理名词 北京nt temporal noun:时间名词 近日, 明代nz other proper noun:其他名词 诺贝尔奖o onomatopoeia:拟声词 哗啦p preposition:介词 在, 把,与q quantity:量词 个r pronoun:代词 我们u auxiliary:助词 的, 地v verb:动词 跑, 学习wp punctuation:标点 ,
ws foreign words:国外词 CPUx non-lexeme:不构成词 萄, 翱z descriptive words 描写,叙述的词 瑟瑟,匆匆命名实体识别命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位在哈工大Pyltp中,NE识别模块的标注结果采用O-S-B-I-E标注形式,其含义如下(参考):LTP中的NE 模块识别三种NE,分别为人名(Nh)、机构名(Ni)、地名(Ns)完整代码:# -- coding: utf-8 --from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizerldir='AgriKG\\ltp\\cws.model' #分词模型dicdir='word' #外部字典text = \"贵州财经大学要举办大数据比赛吗?\"#中文分词segmentor = Segmentor #初始化实例segmentor.load_with_lexicon(ldir, 'word') #加载模型words = segmentor.segment(text) #分词print(text)print(' '.join(words)) #分词拼接words = list(words) #转换listprint(u\"分词:\", words)segmentor.release #释放模型#词性标注pdir='AgriKG\\ltp\\pos.model'pos = Postagger #初始化实例pos.load(pdir) #加载模型postags = pos.postag(words) #词性标注postags = list(postags)print(u\"词性:\", postags)pos.release #释放模型data = {\"words\": words, \"tags\": postags}print(data)print(\" \")#命名实体识别nermodel='AgriKG\\ltp\\ner.model'reg = NamedEntityRecognizer #初始化命名实体实例reg.load(nermodel) #加载模型netags = reg.recognize(words, postags) #对分词、词性标注得到的数据进行实体标识netags = list(netags)print(u\"命名实体识别:\", netags)#实体识别结果data={\"reg\": netags,\"words\":words,\"tags\":postags}print(data)reg.release 输出结果如下图所示,识别出的三个命名实体分别是:“贵州”(B-Ni)表示一个NE开始-机构名,“财经”(I-Ni)表示一个NE中间-机构名,“大学”(E-Ni)表示一个NE结束-机构名PS:虽然导入指定词典,但“贵州财经大学”分词仍然被分割,后续研究中依存句法分析依存句法是由法国语言学家L.Tesniere最先提出它将句子分析成一棵依存句法树,描述出各个词语之间的依存关系也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的如下图所示:哈工大Pyltp的依存句法关系如下图所示参考:https://ltp.readthedocs.io/zh_CN/latest/appendix.html完整代码:# -- coding: utf-8 --from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import Parserfrom pyltp import NamedEntityRecognizerldir = 'AgriKG\\ltp\\cws.model' #分词模型dicdir = 'word' #外部字典text = \"贵州财经大学要举办大数据比赛吗?\"#中文分词segmentor = Segmentor #初始化实例segmentor.load_with_lexicon(ldir, 'word') #加载模型words = segmentor.segment(text) #分词print(text)print(' '.join(words)) #分词拼接words = list(words) #转换listprint(u\"分词:\", words)segmentor.release #释放模型#词性标注pdir = 'AgriKG\\ltp\\pos.model'pos = Postagger #初始化实例pos.load(pdir) #加载模型postags = pos.postag(words) #词性标注postags = list(postags)print(u\"词性:\", postags)pos.release #释放模型data = {\"words\": words, \"tags\": postags}print(data)print(\" \")#命名实体识别nermodel = 'AgriKG\\ltp\\ner.model'reg = NamedEntityRecognizer #初始化命名实体实例reg.load(nermodel) #加载模型netags = reg.recognize(words, postags) #对分词、词性标注得到的数据进行实体标识netags = list(netags)print(u\"命名实体识别:\", netags)#实体识别结果data={\"reg\": netags,\"words\":words,\"tags\":postags}print(data)reg.release #释放模型print(\" \")#依存句法分析parmodel = 'AgriKG\\ltp\\parser.model'parser = Parser #初始化命名实体实例parser.load(parmodel) #加载模型arcs = parser.parse(words, postags) #句法分析#输出结果print(words)print(\"\t\".join(\"%d:%s\" % (arc.head, arc.relation) for arc in arcs))rely_id = [arc.head for arc in arcs] # 提取依存父节点idrelation = [arc.relation for arc in arcs] # 提取依存关系heads = ['Root' if id == 0 else words[id-1] for id in rely_id] # 匹配依存父节点词语for i in range(len(words)):print(relation[i] + '(' + words[i] + ', ' + heads[i] + ')')parser.release 输出结果如下所示,其中ATT表示定中关系,如“贵州-大学”、“财经-大学”;SBV表示主谓关系,如“大学-举办”;ADV表示状中结果“要-举办”;HED表示核心关系“举办-Root”,即“举办大数据”补充:arc.head表示依存弧的父节点词的索引,arc.relation表示依存弧的关系arc.head中的ROOT节点的索引是0,第一个词开始的索引依次为1、2、3语义角色标注该部分代码仅供博友们参考,作者还在深入研究中#语义角色标注from pyltp import SementicRoleLabellersrlmodel = 'AgriKG\\ltp\\pisrl.model'labeller = SementicRoleLabeller #初始化实例labeller.load(srlmodel) #加载模型words = ['元芳', '你', '怎么', '看']postags = ['nh', 'r', 'r', 'v']arcs = parser.parse(words, postags) #依存句法分析#arcs使用依存句法分析的结果roles = labeller.label(words, postags, arcs) #语义角色标注# 打印结果for role in roles:print(role.index, \"\".join([\"%s:(%d,%d)\" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))labeller.release #释放模型输出结果如下:http://md.aclickall.com/上面的例子,由于结果输出一行,所以“元芳你怎么看”有一组语义角色其谓词索引为3,即“看”这个谓词有三个语义角色,范围分别是(0,0)即“元芳”,(1,1)即“你”,(2,2)即“怎么”,类型分别是A0、A0、ADV希望这篇基础性文章对你有所帮助,如果有错误或不足之处,还请海涵原文链接:https://blog.csdn.net/Eastmount/article/details/90771843https://blog.csdn.net/Eastmount/article/details/92440722最近,大家都在谈论高考志愿报考话题,Python大本营也发起投票,欢迎大家与我们交流(本文经作者授权微信平台首发于AI科技大本营,转载请微信联系1092722531)【End】热 文推 荐☞小米崔宝秋:小米 AIoT 深度拥抱开源☞为什么 C 语言仍然占据统治地位?☞苹果应用审核团队:每人日审百款 App
☞华为在美研发机构 Futurewei 意欲分家?☞老司机教你如何写出没人敢维护的代码
☞Python有哪些技术上的优点?比其他语言好在哪儿?☞上不了北大“图灵”、清华“姚班”,AI专业还能去哪上?☞公链史记 | 从鸿蒙初辟到万物生长的十年激荡……☞边缘计算容器化是否有必要?☞马云曾经偶像,终于把阿里留下的1400亿败光了
你点的每个“在看”,我都认真当成了喜欢

(图片来源网络,侵删)





0 评论