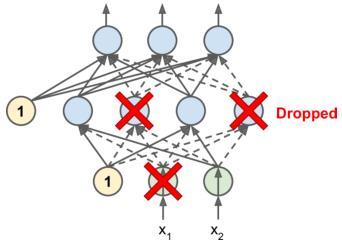
近些年来人工智能的热度与日俱增,5G + AI + IoT几乎成为了人们对于未来的定义。Deepmind开发的AlphaGo围棋AI,在2016年先后击败了李世乭和柯洁,扯下了人类智慧的最后一块遮羞布。被誉为强化学习之父的Rich Sutton老先生,也在2017年作为一名研究科学家加入了Google Deepmind。University of Alberta, Edmonton, CanadaRichard S. Sutton, Univerisyt of Alberta, 2015本人有幸上过的Rich Sutton老先生的课,对于强化学习了解一点皮毛。这里我们就简单介绍一下强化学习的基本知识,并利用深度强化学习(神经网络+Q-Learning)来训练一个简单的游戏AI。在本文中,我们会设计一个AI agent(虚拟玩家),并从头开始训练它学习小游戏贪吃蛇的玩法。我们会利用Keras和Tensorflow来实现一个深度强化学习算法。强化学习算法的核心就是虚拟玩家(agent)根据自身的状态(state)做出动作(action),并且得到反馈(reward),并利用反馈来改进今后的策略(policy)。agent并不知道任何游戏规则,我们的目的是让这个系统自己不断训练,在学习中提高游戏得分,并最终形成一个可行的游戏策略。我们会看到Deep Q-Learning算法是怎么一步步学习游戏的规则,从一开始的无所适从,随处乱走,到仅仅5分钟后就学习出了可行的策略并且在游戏中轻松获得50分以上。左图:刚开始训练;有图:训练后。图片来源:Mauro Comi一、游戏环境搭建我们利用python和Pygame简单搭建了基础的游戏环境,这样我们就可以直观地观察agent的训练过程了。从上图中我们可以很清楚地看到,刚开始的时候,agent没有任何策略,只能盲目地随机走动。而在训练后,agent的策略已经十分理想了。二、马尔可夫决策过程(MDP)MDP是一个用于给策略制定建模的数学框架,常被用来研究最优化问题。强化学习利用MDP来做出决策,而不是像传统的监督学习一样依赖输入(input)和对应的正确答案(target)来训练。在强化学习中,有两个主要的部分:环境(environment)和虚拟玩家(agent)。每当agent做出动作(action),环境就会依据agent当前所处的状态(state)来给出反馈(reward)。在贪吃蛇游戏中,如果我们假设吃到果实的reward为1,而因为撞墙或者撞到蛇的身体而game over的reward为-1的话。那么我们就可以说,从果实旁边(state)前进一步(action)的反馈(reward)是1。类似的,在墙边(state),向墙前进一步(action)的反馈(reward)就是-1。agent的目标就是学习在给定的state(包括蛇的位置,果实的位置等等游戏环境)下,什么样的action可以最大化reward。agent用于做出决策的策略就是policy,我们可以把想象成state到action的映射,指导了agent在给定state下应该做出哪个action。例如在贪吃蛇游戏中,state就是所有可能游戏状态的集合(蛇的位置,果实的位置,地图的大小,蛇的长度等等),而action就是蛇的所有可能动作集合(向上,向下,向左,向右)。下图为一个MDP的简单例子,由三个state,两个action,两个reward组成的马尔可夫决策过程(MDP):由三个state,两个action,两个reward组成的马尔可夫决策过程(MDP),图片来自Wikipedia二、Q-learning算法Q-table是一个state和可能action的关联矩阵,矩阵中的数值就是在训练过程中根据reward算出该action的预期reward,代表了该action的成功率。利用Q-table,我们可以找出agent的最佳策略(policy)。很明显,Q-table只能处理有限个state,如果state的数量十分巨大的话我们很可能会遇到问题。这个时候就需要利用深度神经网络了。每当系统给出了reward,我们可以通过公式(Bellman equation)来更新Q-value:Bellman equationQ-learing部分的算法核心大致如下:游戏开始,随机初始化Q-value系统通过观察获取当前状态(State)根据状态s, agent执行动作(action)。动作可以随机生成,或者查询已有的Q-table。在训练初期阶段,系统通常会倾向于随机策略,来探索(exploration)更多的action和对应的reward。在训练后期阶段,系统会越来越依赖已有的知识(exploitation)。当agent执行了action之后,环境(environment)会给出reward。然后agent到达下个状态(state')并根据Bellman equation更新Q-value。并且,对于每一步,存储state, action, state', reward, 游戏是否结束等信息,用于将来训练神经网络,这一步称为Replay Memory。持续重复上面三步骤,直到本轮游戏结束。三、深度神经网络(Deep Neural Network)State: 代表了agent观察到了环境的状态,我们也将state用于神经网络的输入。具体而言,state是包含了11个布尔变量的array。Loss:深度神经网络利用损失函数(loss function)来减少衡量真实结果和预测值的差距。神经网络的目标是最小化lost。这我们这个例子自,损失函数是:Deep Neural Network:我们使用的深度神经网络有3个中间层(hidden layer)和120个神经元(neuron)。这个神经网络使用state作为输入,返回3个值,分别对应向左,向右,直走这三个动作。最后一层使用了Softmax函数。Deep Neural Network by Mauro Comi四、训练结果在训练了短短5分钟,在150轮游戏之后,agent已经从毫无策略的乱走,到摸索出了一套有效的策略,并且能够获得50分以上的游戏成绩了。
如图,横坐标为游戏轮数,纵坐标为游戏得分。可以看出,在前50轮,得分很低,agent主要在探索环境。而在后50轮,agent不再执行随机探索策略,而是利用已经学习到的policy做出动作,所以得到了较高的得分。五、总结到这里,我们就已经学习了强化学习的基本知识,并且了解了Deep Q-learing算法的基本原理,还通过贪吃蛇这个小游戏检验了DQN算法的效果。大家觉得短短5分钟的训练效果怎么样呢?感兴趣的朋友可以查看源码验证一下,甚至可以改进算法提升一下训练效果~reference:https://towardsdatascience.com/how-to-teach-an-ai-to-play-games-deep-reinforcement-learning-28f9b920440ahttps://github.com/maurock/snake-ga我是零度橙子,科技达人,谷歌认证云计算架构师,AWS认证devops专家,欢迎大家关注我,了解有用有趣的科技知识~




0 评论