- APP神圣官网 > 软件快讯 > 正文
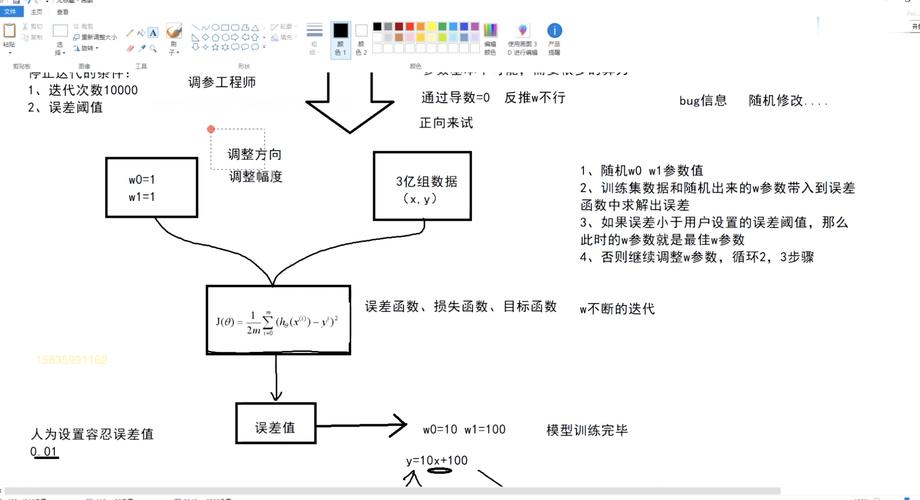
在学习人工智能之前,我们大多都需要提前了解一些有关机器学习的内容这篇文章里,作者就阐述了机器学习训练“模型”的几个步骤,一起来看看学习人工智能,必须要了解机器学习我们可以把机器学习比喻成大脑学习大脑学习的成果是“智慧”,机器学习的成果就是“模型”机器学习训练“模型”有四个步骤:第一步:“收集数据”好比“收集知识”第二步:“训练模型”好比“消化理解”第三步:“模型评估”好比“考试打分”第四步:“模型部署”好比“走进社会”一、收集数据机器学习的基本理念是使用过去学习到的经验知识来预测新的问题,这个和大脑学习过程很像,我们需要见多识广,收集大量数据为训练模型收集到的数据随机分成两部分:训练数据集:用于“消化理解”的题目测试数据集:用于“考试打分”的题目这些题目在机器学习里称之为“样本”“token”则是指数据集中最小有意义单元,如:一个单词、一个数字、一个汉字一般用token量来表示所用到的数据集大小;据说GPT4用了13万亿token用于训练二、训练模型“智慧”从题目中的“信息”中推理出“答案”;“模型”从样本中的“特征”中推理出“标签”以一个预测冰激凌销售收入的模型为案例:特征:气温x1、降雨量x2、是否节假日x3…标签:收入yy = f(x1,x2,x3….)机器学习最神奇的事情就是科学家们会选择合适的数学算法,这种算法可以从大量由x和y组成的样本里自行推导出f那些天才科学家们发明过很多算法,还起了让人一脸懵逼的算法名称比如:“随机森林”、“k近邻算法”、“生成对抗”、“支持向量机” 等等除了算法,我们还常听到模型的“参数”,它是指那些可调整的变量,用于控制模型的行为和性能最常见的一种参数是“权重参数”;可以理解为是函数里的a、b、cy = f(ax1,ax2,cx3….)据说GPT4参数量达到了恐怖的1.8万亿三、模型评估很多时候我们自以为对知识“消化理解”了,但真正要用的时候却经常出错,我们需要“考试打分”这一环节帮我们把把关,这不仅仅是为了向社会证明我们应该具备了某种能力,更重要的是可以指导我们如何进行查漏补缺在机器学习里,用“测试数据集”去考验“f”并给出一个评价分数的过程就是模型评估常见的术语有:1)过拟合:训练高分但考试低分模型在训练集上的表现好,但是在测试集上的表现不佳2)泛化:能够举一反三的能力指训练好的模型对未见过的数据的适应能力3)精度:答对的题目数/题目总数模型预测正确的样本数占总样本的比例所谓的“模型迭代”就是通过不断优化或新增训练数据集,选择更合适的“算法”或者“参数”去训练出新的“f”,以便能在测试数据集中拿到一个更高的分数四、模型部署就像“考试打分”不是我们学习最终目的,模型评估的分数就算再高也要“走进社会”去部署运用才能发挥模型真正的价值学海无涯,机器学习同样如此,模型部署是下一轮机器学习的开始对于已部署生产环境的模型需要建立监控机制,定期监测模型性能和预测结果,及时发现并解决模型退化或失效的问题,在使用者允许的情况下在生产环境所遇到的新情况也会是下一轮“收集数据”的样本,以便不断提高模型的准确性本文简单概述了机器学习的四个步骤机器学习和大脑学习很像;“收集数据”是“学习准备”;“训练模型”是“埋头苦学”;“模型评估”是“反思复盘”;“模型部署”是“大展拳脚”八字口诀:“收集训练评估部署”世界变化只会越来越快,我们一起学习AI知识,紧跟时代潮流~
联系我们
在线咨询:







0 评论